Umělá inteligence a strojové učení
Umělá inteligence a strojové učení
Umělá inteligence (AI, angl. artificial intelligence) je obor informatiky zabývající se vytvářením programů pro řešení složitých problémů – problémů, které by obvykle vyžadovaly lidskou inteligenci.
- Všeobecný přehled poskytuje kapitola základy umělé inteligence. V ní se zabýváme např. tím, co umělá inteligence je a co není, co umí a co neumí, co je realita a co fikce.
- Druhá kapitola představuje několik aplikací umělé inteligence – zpracování přirozeného jazyka, počítačové vidění a robotiku.
- Třetí kapitola se věnuje metodám umělé inteligence – technikám prohledávání stavového prostoru, splňování podmínek a optimalizace.
Dvě kapitoly pak věnujeme strojovému učení – podoblasti umělé inteligence zabývající se tvorbou programů, které se učí z dat.
- Kapitola základy strojového učení popisuje princip a postup strojového učení a věnuje se také riziku zkreslení (předpojatosti).
- Poslední kapitola rozebírá podrobněji metody strojového učení jako je lineární regrese, rozhodovací stromy a neuronové sítě.
Základy umělé inteligence

Umělá inteligence je obor informatiky zabývající se vytvářením programů schopných provádět úkoly, které by obvykle vyžadovaly lidskou inteligenci. Umělá inteligence zahrnuje například porozumění jazyku, rozpoznávání obrazu a řešení složitých problémů jako je řízení auta. V rámci základního přehledu najdete na Umíme následující témata:
- Vymezení umělé inteligence – co je to umělá inteligence a co umělá inteligence není.
- Využití a schopnosti umělé inteligence – co umělá inteligence umí a co neumí.
- Umělá inteligence: realita a fikce – co funguje v realitě a co pouze ve sci-fi představách.
- Historie umělé inteligence – klíčové trendy a milníky vývoje umělé inteligence.
- Umělá inteligence: pojmy – přehled základních pojmů používaných v oblasti umělé inteligence.
Vymezení umělé inteligence
Umělá inteligence (AI, angl. artificial intelligence) označuje programy řešící složité problémy (např. hraní šachů nebo řízení auta) a také obor informatiky zabývající se vytvářením těchto programů. Umělá inteligence nejsou jen roboti, častěji jde o počítačový program bez fyzické podoby. Umělá inteligence má využití všude, kde existují složité problémy, například ve zpracování přirozeného jazyka, robotice a počítačovém vidění.
Definice umělé inteligence
Neexistuje jednotná definice umělé inteligence. Někdy se za umělou inteligenci považují programy, které se chovají jako lidé, to je ale omezující v tom, že lidé se často nechovají inteligentně, dělají chyby a některé složité problémy řešit neumí. Vhodnější je proto považovat za umělou inteligenci programy, které se chovají inteligentně (racionálně). Inteligentní chování znamená, že se program snaží maximalizovat očekávaný užitek (např. pravděpodobnost výhry v šachu).
Turingův test
V polovině 20. století navrhl Alan Turing známý test na rozpoznání umělé inteligence: Pokud nejsme při písemné komunikaci schopni rozlišit, zda si povídáme s člověkem nebo programem, pak můžeme daný program považovat za umělou inteligenci. Turingův test odpovídá definici umělé inteligence jako programu, který se chová jako člověk, což je omezující – aby program prošel tímto testem, nesmí odpovídat příliš rychle a musí záměrně dělat chyby, jaké by udělal člověk (např. při násobení velkých čísel).
AI efekt
Umělá inteligence řeší složité problémy – problémy, jejichž řešení ještě donedávna vyžadovalo lidskou inteligenci. Jakmile si zvykneme na to, že daný problém umí počítače řešit, přestaneme ho považovat za složitý a program, který ho řeší, přestaneme považovat za umělou inteligenci. Tento neustálý posun toho, co považujeme za umělou inteligenci, se označuje jako AI efekt.
Úzká vs. obecná umělá inteligence
Úzká umělá inteligence umí řešit pouze určitý specializovaný typ problému (např. hrát šachy, rozpoznávat obličeje na fotografiích), zatímco obecná umělá inteligence (AGI z angl. artificial general inteligence) umí řešit libovolný problém alespoň tak dobře jako člověk. Obecná umělá inteligence zatím neexistuje. (Někdy se pro toto rozlišení používají také pojmy „slabá a silná AI“, ty však při přesném použití mají trochu odlišný význam – rozlišují, zda AI má vlastní vědomí.)
Související pojmy
Umělá inteligence, strojové učení a neuronová síť nejsou synonyma. Umělá inteligence často využívá strojové učení (učení z dat či zkušenosti), existuje však i mnoho metod umělé inteligence, které strojové učení nevyužívají. Neuronová síť je pak pouze jeden z mnoha modelů využívaných ve strojovém učení.
Využití a schopnosti umělé inteligence
Mezi typické aplikace umělé inteligence patří například:
- robotika (např. robotický vysavač, průmysloví roboti, samořídící auta),
- doporučovací systémy (např. doporučování filmů, knih),
- zpracování přirozeného jazyka (např. překládání mezi jazyky, vyhledávání informací, detekce spamu),
- rozvrhování a plánování (např. plánování výroby v továrně),
- zpracování obrazu (např. rozpoznání osob či SPZ na fotce),
- počítačové hry (např. ovládání chování nehratelných postav).
Umělá inteligence má využití především v oblastech, kde se vyskytují opakované, repetitivní činnosti, např. obsluha výrobních pásů, řízení strojů, základní administrativní úkony.
Umělá inteligence zatím nemá schopnosti, které vyžadují složitější manuální operace (např. stříhání vlasů), koordinaci rozmanitých činností (např. rekonstrukce bytu), sociální dovednosti a empatii (např. zdravotnictví) či kreativitu a samostatné formulování cílů (např. výzkum).
Umělá inteligence: realita a fikce
Umělá inteligence se často vyskytuje i v uměleckých dílech (knihy, filmy, divadelní hry). Její zobrazení ve fikci však často neodpovídá skutečnosti a je tedy užitečné umět rozlišovat, co je realita a co fikce. Fikce neumožňuje získat lepší představu o aktuální podobě a schopnostech umělé inteligence, ale přináší zajímavé etické a filozofické otázky.
Příklady známých fiktivních robotů a programů:
- Golem, Frankenstein: Umělé myslící stroje z pověstí či knih, předchází použití slova robot.
- Roboti v divadelní hře R.U.R. od Karla Čapka (první použití slova robot).
- HAL 9000: Program řídící vesmírnou loď z filmu 2001: Vesmírná odysea. Známý tím, že se snaží zabít kosmonauty, aby dosáhl splnění zadaného úkolu.
- Umělá inteligence ve filmu Matrix, která zotročila lidstvo jako zdroj energie.
- Marvin: Paranoidní robot z knižní série Stopařův průvodce po galaxii.
- KITT: Inteligentní auto ze seriálu Knight Rider.
- Číslo 5: Robot, který se stal vědomým po zásahu bleskem.
- R2D2, C-3PO, BB8: Roboti z filmové série Hvězdné války.
- SkyNet: Superinteligence usilující o vyhlazení lidstva ve filmech Terminátor.
- Bender: Humanoidní robot ze seriálu Futurama.
- WALL-E: Robot (sběrač odpadků) ze stejnojmenného filmu.
Fiktivní jsou také Tři zákony robotiky od Isaaca Asimova, které pochází původně ze série povídek. Tyto fiktivní zákony se staly ovšem základem pro mnoho diskuzí morálních problémech při vývoji robotů.
Příklady známých reálných robotů a programů:
- Deep Blue: Šachový program, porazil lidského velmistra Garry Kasparova.
- IBM Watson: Program schopný odpovídat otázky.
- AlphaGo: První program, který porazil velmistra v Go.
- Eliza: První známější chatovací program (1966).
- ChatGPT: Chatovací program z nedávné doby (2022).
- Alexa, Siri: Virtuální pomocníci.
- ASIMO, Pepper: Humanoidní roboti.
Historie umělé inteligence
Před rokem 1950
- Karel Čapek napsal divadelní hru R.U.R, ve které bylo poprvé použito slovo robot (1920).
- První počítače, používané především pro výpočty v průběhu druhé světové války (např. pro dešifrování).
- První model neuronu, který se stal základem neuronových sítí.
1950–1960
- Základy umělé inteligence jako vědy, první principy algoritmů umělé inteligence.
- Alan Turing navrhuje test strojové inteligence (Turingův test), kdy člověk musí rozpoznat, zda komunikuje s počítačem či člověkem.
- Začátek vývoje průmyslových robotů.
1960–1970
- Využívání pravidlových systémů a logického odvozování, rozvoj technik prohledávání stavového prostoru.
- První chatovací programy (např. Eliza).
- První programy hrající deskové hry (např. dámu, piškvorky) na úrovni amatéra.
- První samostatně se pohybující roboti (např. Shakey).
- Základy zpracování přirozeného jazyka, první demonstrace strojového překladu.
- Základy rozpoznávání obrazu.
1970–1990
- Na konci 70. let (a znova na konci 80.let ) došlo kvůli nenaplněným očekáváním k útlumu počátečního optimismu ohledně umělé inteligence, pokles financování (období nazývané „zima umělé inteligence“).
- Rozvoj tzv. „expertních systémů“ využívajících znalosti a pravidla získaná od odborníků na daný problém. (Strojové učení se zatím příliš nepoužívá.)
1990–2000
- Rozvoj pravděpodobnostních a statistických metod umožňujících práci s nejistotou.
- Rozvoj internetu a webu, využití umělé inteligence pro vyhledávání.
- Program Deep Blue porazil velmistra ve hře šachy. (Program byl založený na prohledávání stavového prostoru; strojové učení se začalo výrazně používat až později.)
- Samořiditelná auta použitelná v omezených podmínkách a za kontroly.
2000–2010
- Se zvyšováním množství dostupných dat a výpočetního výkonu se stává populárnější strojové učení. (Neuronové sítě se však zatím stále používají spíše okrajově, jiné modely dosahují lepších výsledků.)
- Rozvoj doporučovacích systémů (Netflix, YouTube, Amazon).
- Začínají se prodávat robotické vysavače.
- Samořiditelná auta zvládající i dlouhé terénní trasy nebo realistický provoz (zatím bez většího samostatného použití v běžném provozu).
- IBM Watson vyhrál nad lidmi ve hře Jeopardy! (odpovídání vědomostních otázek).
2010–2020
- Díky dalšímu zvyšování množství dostupných dat a výpočetního výkonu nastává prudký rozvoj oblasti „hluboké učení“ – využití hlubokých neuronových sítí trénovaných na velmi rozsáhlých datech.
- Rozpoznávání řeči na úrovni srovnatelné s lidmi, rozšíření hlasových virtuálních pomocníků (Siri, Alexa).
- Výrazné zlepšení rozpoznání obrazu (např. obličejů na fotografiích).
- Vítězství umělé inteligence nad lidmi v dalších hrách: go, poker. Schopnost hrát jednoduché počítačové hry čistě na základě obrazového vstupu.
- Autonomní auta použitelná v běžném provozu.
2020–2030
- Využití neuronových sítí pro určování 3D struktury proteinů (AlphaFold).
- Rozvoj generativní umělé inteligence: vytváření obrázků, generování textů, chatovací programy.
- Vznikají první zákony (např. pakt EU) regulující použití umělé inteligence.
Umělá inteligence: pojmy
Pro pochopení textů o umělé inteligenci je užitečné znát řadu pojmů. Jejich přesný význam nje často komplikovaný a ne úplně jednoznačný (mají třeba více významových odstínů a použití). Naše stručné popisy se snaží zachytit pouze jejich základní podstatu.
| pojem | popis |
|---|---|
| umělá inteligence | programy schopné provádět úkoly vyžadující inteligenci |
| inteligentní agent | program interagující s prostředím a využívající umělou inteligenci |
| úzká umělá inteligence | umí řešit pouze určitý specializovaný typ problému (např. hrát šachy, rozpoznávat obličeje na fotografiích) |
| obecná umělá inteligence | umělá inteligence, která umí řešit libovolný problém (hrát libovolnou deskovou hru, provádět nové operace s fotografiemi na základě slovního popisu a podobně) |
| superinteligence | umělá inteligence, která vysoce převyšuje schopnosti lidí ve všech oblastech |
| generativní umělá inteligence | umělá inteligence schopná vytvářet nový obsah (obraz, text, zvuk) |
| vysvětlitelná umělá inteligence | metoda, pro niž lze poskytnout vysvětlení, proč se chová tak, jak se chová |
| hrubá síla | zkoušení všech možností |
| prohledávání stavového prostoru | techniky umělé inteligence pro hledání optimálních plánů |
| expertní systém | umělá inteligence využívající znalosti a pravidla získaná od odborníků na daný problém |
| strojové učení | techniky založené na automatizovaném učení z dat; ne všechny přístupy k umělé inteligenci využívají strojové učení (např. umělá inteligence pro řešení sudoku nepoužívá strojové učení z dat) |
| rozhodovací strom | model strojového učení predikující výstup na základě podmínek |
| neuronová síť | model strojového učení volně inspirovaný mozkem |
| perceptron | nejjednodušší neuronová síť s jediným neuronem |
| hluboké učení | podoblast neuronových sítí využívající hierarchickou reprezentaci vlastností |
| genetický algoritmus | přístup inspirovaný biologickými procesy dědičnosti / evolučními mechanismy |
| posilované učení | podoblast strojového učení, zkušenostní učení na základě odměn a trestů |
| Bayesovská síť | pravděpodobnostní model zachycující vztahy mezi událostmi |
| fuzzy logika | typ logiky umožňující pracovat s nepřesností a nejistotou |
| robotika | vývoj strojů, které se pohybují v prostoru |
| humanoidní robot | svou konstrukcí a vzhledem připomíná člověka (též označovaný android, zvlášť pokud má povrchový materiál připomínající kůži) |
| autonomní robot | robot, který pracuje samostatně |
| zpracování přirozeného jazyka | strojové zpracování běžných lidských jazyků (např. čeština, angličtina, němčina) |
| chatovací program | program, který je schopen konverzovat s člověkem (většinou psanou formou) |
| počítačové vidění | získávání informací z obrazových dat |
| rozpoznávání řeči | automatický převod mluvené řeči do textu |
| syntéza řeči | umělá tvorba lidské řeči |
| doporučovací systém | systém, který poskytuje personalizované doporučení pro uživatele (např. film, který by se uživateli mohl líbit) |
| úloha s omezujícími podmínkami | úloha nalézt hodnoty proměnných, které splňují různá provázaná omezení (např. sudoku) |
| zkreslení, předpojatost | systematická chyba, která vede k neférovým důsledkům |
| halucinace | smyšlená nesprávná odpověď generativní umělé inteligence prezentovaná jako fakt |
| deepfake | využití umělé inteligence k vytvoření realistických podvrhů (typicky videa) |
| emergentní chování | komplexní chování vznikají interakcí mnoha jednoduchých prvků systému |
| dataset | data (sada příkladů)pro strojové učení |
| korpus | rozsáhlá kolekce textových dokumentů |
| model | řešení úlohy (mapuje vstupy na výstupy) |
| jazykový model | model odhadující pravděpodobnost dalšího slova v rozepsaném textu |
| velký jazykový model | rozsáhlá neuronová síť predikující pravděpodobnost dalšího slova |
| GPT | generativní předtrénovaný transformátor, typ velkého jazykového modelu použitý v chatovací aplikaci ChatGPT |
| AI efekt | jev, že to, co považujeme za umělou inteligenci se časem posouvá podle toho, zda jsme si už na to zvykli |
| stavový prostor | všechny možné stavy úlohy a přechody mezi nimi |
| deterministický | jednoznačně určený provedenou akcí, bez náhody |
| stochastický | zahrnující náhodu (např. hod kostkou) |
| diskrétní | úloha s konečným počtem stavů (např. šachy) |
| predikce | odhadnutí kategorie nebo hodnoty nějakého atributu daného příkladu |
| prompt | uživatelský vstup (otázka, úkol) pro generativní umělou inteligenci |
| token | základní jednotka při práci s textem (slovo nebo část neznámého slova) |
| vnoření slov (word embedding) | reprezentace slov pomocí vektoru reálných čísel |
| Lisp, Prolog | programovací jazyky, které se dříve hodně využívaly v umělé inteligenci |
| Python | moderní programovací jazyk, který je mj. hodně využíván pro strojové učení a umělou inteligenci |
Aplikace umělé inteligence
Umělá inteligence a strojové učení mají využití v mnoha oblastech aplikované informatiky. Na Umíme najdete základní přehled o následujících oblastech:
- zpracování přirozeného jazyka (např. detekce spamu, odpovídání na otázky)
- robotika (např. robotický vysavač, samořídící auta)
- počítačové vidění (např. rozpoznání osob či SPZ na fotce)
Co umělá inteligence v dnešní době umí a co ne, si můžete procvičit v rámci tématu Využití a schopnosti umělé inteligence.
Zpracování přirozeného jazyka
Zpracování přirozeného jazyka (angl. natural language processing) je obor na pomezí informatiky (specificky umělé inteligence) a lingvistiky, který zkoumá analýzu a generování psaného či mluveného slova. Mezi úlohy zpracování přirozeného jazyka patří:
- klasifikace textu (detekce spamu, určení žánru, určení autorství)
- shlukování textů (vytvoření skupin podobných zpráv nebo souvisejících soudních případů)
- korektura textu (kontrola pravopisu – spell-check, kontrola gramatiky – grammar check)
- generování textu (odpovídání na otázky, shrnování textu, strojový překlad)
- rozpoznávání řeči (řeč → text) a syntéza řeči (text → řeč)
- popisování obrázků (obrázek → text) a generování obrázků (text → obrázek)
Pravidlový přístup
Dříve se na tyto úlohy využívaly pravidlové přístupy snažící se zachytit pravidla daného jazyka (např. časování sloves). Analýza textu byla rozdělena do několika navazujících úrovní (jazykových rovin): 1. morfologie (konstrukce slov), 2. syntaxe (skládání vět), 3. sémantika (význam vět) a 4. pragmatika (použití vět v kontextu). Postihnout přirozený jazyk pomocí pravidel se však ukázalo jako obtížné.
Komplikace zpracování přirozeného jazyka
Každé pravidlo má řadu výjimek a texty v přirozeném jazyce obsahují překlepy a jiné chyby, které je také potřeba modelovat, chceme-li textu porozumět. Další komplikací je nejednoznačnost na mnoha úrovních: homonyma, tj. slova s více možnými významy (los, stát, koruna), věty s více možnými významy („Sněz rychle chladnoucí polévku.“), zájmena odkazující se na dříve uvedené objekty (anafory) a další odkazy do jiných částí textu nebo i mimo něj (já, teď). Význam vět nelze vždy určit z významu dílčích slov, například při použití idiomů, metafor a metonymií.
Strojové učení
V dnešní době se zpracování přirozeného jazyka řeší téměř výhradně využitím strojového učení, které dosahuje výrazně lepších výsledků než pravidlové přístupy. K učení se využívají rozsáhlé kolekce textových dokumentů označované jako korpusy. Korpusy obsahují například digitalizované knížky, online encyklopedie (Wikipedia), někdy dokonce texty z většiny dostupných webových stránek a můžou tak mít i miliardy slov.
Výstupem strojového učení je jazykový model, který odhaduje pravděpodobnost dalšího slova v rozepsaném textu. Takový model lze pak využít ke generování textu v chatbotech (opakovaným výběrem některého z pravděpodobných dalších slov) nebo výběru nejpravděpodobnější věty z několika kandidátů (to se hodí třeba při rozpoznávání řeči nebo strojovém překladu). Jazykové modely realizované pomocí rozsáhlých neuronových sítí s miliardami parametrů (které se nastavují během učení) se označují jako velké jazykové modely (angl. large language models, LLM).
ChatGPT
Příkladem velkého jazykového modelu je GPT, generativní předtrénovaný transformátor. Jde o generativní model, protože umožňuje generovat text. Je předtrénovaný na rozsáhlém datasetu textů z většiny dostupných webových stránek. Transformátor (angl. transformer) je populární typ neuronové sítě umožňující efektivní učení na takto rozsáhlých datech. ChatGPT je pak název konkrétní aplikace (chatbota) využívající na pozadí tento velký jazykový model.
Reprezentace textu
Základní jednotkou při práci s textem jsou tokeny, což jsou typicky buď známá slova nebo části neznámých slov. Možných tokenů v jednom jazyce je pak třeba několik desítek tisíc. Rozdělení textu na tokeny se označuje jako tokenizace. Pro některé aplikace je výhodné slova převést do jejich základního tvaru, tzv. lemma (jablek → jablko, jsme → být).
Jednotlivá slova se často reprezentují pomocí tzv. vnoření slov (angl. word embeddings) jako vektory reálných čísel v mnohodimenzionálním prostoru. Slova podobného významu jsou v tomto prostoru blízko sebe.
Skupiny slov lze pak reprezentovat buď jako množinu, tedy bez ohledu na pořadí (angl. bag of words), nebo se zachováním pořadí jako tzv. n-gramy (např. bigramy jsou dvojice po sobě jdoucích slov).
Robotika se zabývá vývojem robotů, tedy strojů, které se pohybují v prostoru, vnímají své okolí a na základě jeho stavu se rozhodují. Roboti mají uplatnění v průmyslu (robotická ramena), dopravě (autonomní auta) i domácnosti (robotický vysavač).
Je „kuchyňský robot“ robot?
Navzdory pojmenování kuchyňský robot technicky robotem spíše není, protože nevnímá své okolí a nedělá žádná autonomní rozhodnutí.
Slovo „robot“ je odvozené ze slova „robota“ (práce poddaných) a bylo poprvé použito v divadelní hře hře R.U.R. (Rossumovi univerzální roboti) Karla Čapka v roce 1920. Android je označení pro humanoidní roboty, tedy roboty, kteří mají lidskou podobu. Robot však obecně lidskou podobu mít nemusí, pro mnohé aplikace to není ani potřeba, ani žádoucí (např. robotický vysavač). Měl by ale mít nějakou mechanickou část. (Pro čistě virtuální roboty, tedy programy automatizující činnosti, se někdy používá pojem bot.)
Části robota
Senzory umožňují robotovi vnímat prostředí. Několik příkladů:
- GPS = určování polohy pomocí družic obíhajících Zemi
- radar = měření vzdáleností od okolních objektů pomocí radiových vln
- lidar = měření vzdáleností od okolních objektů pomocí světelných paprsků (měří čas, za jak dlouho se vrátí)
- sonar = měření vzdálenosti pomocí zvukových (typicky ultazvukových) vln
- kamera = zachycení obrazu, užitečné pro kategorizaci objektů
- jednotka inerciálního měření (angl. Inertial Measurement Unit, IMU) kombinuje gyroskop, akcelerometr (a někdy také magnetometer) k určení orientace, rychlosti a zrychlení stroje
Řídící jednotka, typicky realizována skrze jednočipový počítač (mikrokontrolér), umožňuje robotovi zpracovat informace ze senzorů a rozhodnout se, jak reagovat.
Efektory umožňují robotovi ovlivňovat prostředí (např. robotická ramena a chapadla) a pohybovat se v něm (např. kola, pásy, robotické nohy).
Umělá inteligence
Umělá inteligence se v robotice využívá například k plánování trasy, lokalizaci robota a rozpoznávání okolních objektů. Tyto úlohy jsou komplikované kvůli tomu, že neznáme přesný stav světa (např. kvůli nepřesným měřením senzorů) a jak se bude svět vyvíjet (např. pohyb ostatních aut). Zdrojem nejistoty je i robot samotný, neboť provedení akcí není dokonale přesné (otočení o 89° místo zadaných 90°). Proto se k řešení využívají pravděpodobnostní modely, které dokáží modelovat i nejistotu. S každým novým měřením senzorů se tato nejistota snižuje, s ubíhajícím časem a pohybem naopak zvyšuje.
Při plánování je potřeba vzít v úvahu konstrukční omezení, kvůli kterým robot nemusí být schopen vykonat libovolný plán (např. auto se nemůže pohybovat po libovolné křivce, proto je parkování náročné). Plánování se proto někdy neprovádí v geometrickém prostoru světa, ale v konfiguračním prostoru daného robota, v němž jednotlivé stavy popisují kompletní stav robota (např. jeho pozici, otočení, rychlost).
Počítačové vidění
Počítačové vidění je oblast umělé inteligence zabývající se získáváním informací z obrazových dat. Obrazová data nejsou jen fotky a obrázky, ale také videa, snímky medicínských měření (rentgen, ultrazvuk) a snímky z různých senzorů (radar, sonar). Typické úlohy počítačového vidění jsou:
- rozpoznání obrazu – určení kategorie objektu (druh květiny na fotce, ručně napsaný znak)
- detekce objektů – identifikace různých objektů včetně jejich lokalizace na snímku (chodci, tváře, dopravní značky)
- segmentace obrazu – rozdělení obrazu na jednotlivé části nebo objekty (oddělení popředí a pozadí fotky, obarvení různých druhů tkání)
Příklady aplikací počítačového vidění
- rozpoznávání naskenovaného textu (OCR z angl. optical character recognition)
- rozpoznávání tváří (identifikace osob na fotkách)
- určení druhu rostliny či zvířete na fotce
- analýza medicínských měření (např. rentgenových snímků)
- kontrola kvality výrobků (automatické odhalení defektů)
- detekce událostí na videu (např. krádež zachycená bezpečnostním kamerovým systémem)
- vyhledávání obrázku podle textového popisu (nebo obrázků podobných zadnému obrázku)
- autonomní auta (např. detekce hranic vozovky, ostatních aut, chodců, rozpoznání dopravních značek)
- roboti vnímající a reagující své okolí (např. chycení předmětu)
Počítačové vidění nelze řešit pomocí ručně zapsaných pravidel. (I tentýž předmět vypadá pokaždé jinak podle toho, jak je daleko, natočený, osvětlený nebo částečně zakrytý.) Proto se využívá strojové učení, kdy se program učí obecné rysy různých objektů na základě velkého množství příkladů. (Pokud se má program naučit klasifikovat různé druhy zvířat, potřebuje k učení fotky všech různých druhů, které má rozlišovat, ideálně v mnoha různých situacích.)
Základní rysy obrázků můžou být například hrany a rohy. Takové rysy lze z původního obrázku získat pomocí konvoluce, což je transformace obrázku, při které je každý pixel nahrazen váženým součtem hodnot pixelů v jeho okolí. Hodnoty vah můžou být různé a označují se jako tzv. konvoluční jádro (angl. kernel). Dříve bylo běžné určit tyto rysy manuálně a použít je jako vstup do jednoduchého modelu.
Dnes se využívají složitější modely, které se automaticky učí vhodné rysy samy extrahovat. (Potřebují však ještě větší množství příkladů než jednodušší modely, které používaly manuálně zadané rysy.) Nejčastěji se využívají hluboké neuronové sítě. Neuronové sítě jsou volně inspirované strukturou mozku, ale jde v podstatě jen o složitou matematickou funkci s mnoha parametry, jejichž hodnoty se učí z dat. Slovo „hluboké“ se zde odkazuje na fakt, že sítě obsahují mnoho vrstev, které postupně zachycují složitější rysy a vzory (hrany → základní geometrické tvary → komplexní tvary → „kočkovitost“ atp.). Na úlohy počítačového vidění se dobře hodí konvoluční neuronové sítě, které obsahují vrstvy provádějící konvoluci. Váhy konvoluce nejsou dané dopředu, učí se z dat.
Metody umělé inteligence
Mnoho algoritmických problémů lze formulovat jako jeden z několika typů úloh umělé inteligence, mezi které patří plánování (hledání nejkratší cesty), splňování podmínek (např. sudoku), optimalizace (hledání minima zadané funkce), predikce (odhad hodnoty či kategorie, např. detekce spamu) a generování (např. odpovídání na otázky). Jakmile se nám podaří problém formulovat jako jeden z těchto typů, můžeme využít standardní postupy a algoritmy k jeho řešení:
- Plánovací úlohy lze řešit pomocí technik prohledávání stavového prostoru (např. prohledávání do hloubky či do šířky).
- Úlohy splňování podmínek lze řešit například kombinací propagace omezení a prohledávání s návratem (backtracking).
- Optimalizační problémy lze řešit postupným budováním řešení (systematicky či hladově), nebo postupným vylepšováním jednoho či více řešení (lokální prohledávání, genetické algoritmy).
- K predikcím a generování se využívá strojové učení, tedy programy, které se učí z dat nebo zkušenosti. (Této rozsáhlé oblasti věnujeme samostatnou kapitolu.)
Úlohy a metody umělé inteligence
Na první pohled vypadá každý nový problém jinak, ale při vhodné abstrakci se často ukáže, že jde o jeden ze známých typů úloh, pro jehož řešení můžeme využít standardní postupy a algoritmy.
Typy úloh umělé inteligence
Mezi typy úloh řešených v umělé inteligenci patří:
- plánování – nalezení (nejkratší) posloupnosti akcí, která nás dostane do cíle (nalezení cesty z bludiště, poskládání Rubikovy kostky, naplánování cesty auta do zadané lokace, řešení Sokobana, Autíček a podobných logických úloh)
- splňování podmínek – nalezení hodnot proměnných, které splňují různá provázaná omezení (tvorba školního rozvrhu, řešení sudoku a podobných logických úloh)
- optimalizace – hledání hodnot proměnných minimalizující nebo maximalizující zadanou funkci (sbalení batohu s nejvyšší hodnotou vybraných předmětů, hledání receptu na nejlepší sušenky)
- řízení – nalezení strategie předepisující vhodnou akci pro různé situace (hraní šachu, jízda auta mezi dvěma křižovatkami)
- predikce – určení kategorie nebo hodnoty nějakého atributu určitého vzorku (detekce spamu, rozpoznání rostliny na fotce, odhad zítřejších srážek)
- generování – vytvoření textu nebo obrázku na základě jiného textu nebo obrázku (odpovídání na otázky, strojový překlad, vygenerování popsaného obrázku)
Mnohé problémy jsou kombinací více typů úloh. Například problém obchodního cestujícího (úloha najít nejkratší cestu, která projde všemi zadanými městy a vrátí se do výchozího bodu) zahrnuje plánování, optimalizaci i splňování podmínek.
Charakteristiky prostředí
Úlohy můžeme dále rozlišovat podle vlastností prostředí, se kterým program interaguje:
- diskrétní vs. spojité (Je možných stavů a akcí pouze spočetně mnoho, nebo existuje plynulé spektrum?)
- plně vs. částečně pozorovatelné (Máme k dispozici všechny informace o aktuálním stavu?)
- statické vs. dynamické (Vyvíjí se prostředí i během toho, co AI přemýšlí?)
- deterministické vs. stochastické (Je vývoj jednoznačně určen provedenou akcí, nebo hraje roli náhoda?)
- přátelské vs. nepřátelské (Hraje prostředí proti nám?)
Příklady prostředí
Většina čistě logických deskových her pro dva hráče (šachy, go, dáma) jsou diskrétní, plně pozorovatelné, statické, deterministické a nepřátelské. Mnohé karetní hry (Prší, Poker, Bang!) jsou pouze částečně pozorovatelné, kostkové hry jsou stochastické. Řízení autonomního auta je spojité, částečně pozorovatelné, dynamické a stochastické, ale není nepřátelské.
Metody umělé inteligence
Tyto úlohy se řeší kombinací různých přístupů:
- rozklad na jednodušší podproblémy
- systematické zkoušení možností (hrubá síla a techniky prohledávání stavového prostoru)
- postupné vylepšování řešení (např. lokální prohledávání a genetické algoritmy)
- logické a pravděpodobnostní odvozování (pravděpodobnost je důležitá pro práci s nejistotou)
- využití vhledu expertů a heuristik (pravidla, která neplatí vždy, ale často pomůžou)
- učení se z dat nebo zkušenosti (strojové učení)
Prohledávání stavového prostoru
Prohledávání stavového prostoru je základem mnoha technik umělé inteligence, využívá se například pro řešení logických úloh, výběr optimálního tahu, hledání nejkratší cesty nebo plánování akcí robota.
Stavový prostor úlohy se skládá ze stavů (možné konfigurace úlohy) a akcí (přechody mezi stavy). Jeden ze stavů je počáteční a alespoň jeden stav je cílový. Přechody můžou mít přidruženou cenu.
Stavový prostor jako graf
Stavový prostor lze reprezentovat ohodnoceným orientovaným grafem, jehož vrcholy odpovídají stavům a hrany akcím. Graf stavového prostoru je pro většinu praktických úloh příliš velký na to, abychom ho celý zkonstruovali v paměti, ale některé prohledávací algoritmy si postupně budují část tohoto grafu.
Plán je libovolná posloupnost akcí. Řešení úlohy je takový plán, který nás dostane z počátečního stavu do cílového. Optimální řešení je řešení, které má nejnižší cenu. (Cena plánu je nejčastěji součet cen jednotlivých přechodů.)
Příklad stavového prostoru (skřítek na mřížce)
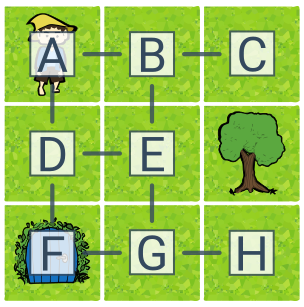
Úlohou je dostat skřítka do domečku. Stavový prostor úlohy má 8 stavů (A–H) a 4 akce (doleva, doprava, dolů, nahoru). Počáteční stav je A, cílový stav F. Optimálním řešením úlohy je např. plán dolů–dolů. Příkladem řešení, které není optimální, je doprava–dolů–dolů–doleva.
Zkoušení všech možností
Nejjednodušším algoritmem, který najde řešení vždy (pokud existuje) je generuj a testuj. Tento algoritmus generuje všechny možné plány a testuje, zda jde o řešení úlohy. Jde tedy o využití hrubé síly, techniky návrhu algoritmů založené na zkoušení všech možností. Zásadní nevýhodou hrubé síly je její časová náročnost. Počet plánů roste exponenciálně vzhledem k délce plánu.
Kolik je různých plánů?
Pokud máme 4 různé akce (P – doprava, D – dolů, L – doleva, H – nahoru), tak existují 4 plány délky 1, ale již 4^2 plánů délky 2 (PP, PD, PL, PH, DP, DD, DL, DH, LP, LD, LL, LH, HP, HD, HL, HH), 4^3 plánů délky 3, 4^4 plánů délky 4, atd.
Obecně, plánů délky n s k akcemi je k^n. Například pro 3 možné akce existuje plánů o 5 krocích 3^5 = 243, plánů o 6 krocích třikrát více, 3^6 = 729, a plánů o 20 krocích je 3^{20}, což už je několik miliard.
Stromové prohledávání
Mnohé plány však nemusí být vůbec proveditelné, nebo se opakovaně vracejí do stejného stavu. Je proto výhodnější testovat plány průběžně po každé akci – jakmile se dostaneme do slepé uličky nebo dříve prozkoumaného stavu, nemusíme žádné další plány začínající touto posloupností akcí prozkoumávat.
Stromové prohledávání je obecný název pro takový způsob prohledávání, kdy postupně konstruujeme a vyhodnocujeme plány po každé akci. Postup prohledávání plánů lze popsat prohledávacím stromem, ve kterém vrcholy reprezentují plány (a současně stav, do kterého se vykonáním plánu dostaneme) a orientované hrany reprezentují akce, které rozšiřují předchozí plán o jeden krok. Prohledávací strom zachycuje stavový prostor tak, jak ho postupně objevuje prohledávací algoritmus. Existuje několik variant stromového prohledávání, které se liší v tom, který plán rozšiřují (tj. který z objevených stavů prozkoumávají jako další):
Prohledávání do hloubky (DFS, angl. Depth First Search) vybírá poslední objevený stav. DFS má dobrou paměťovou složitost, protože si pamatuje pouze plány na aktuální větvi prohledávacího stromu.
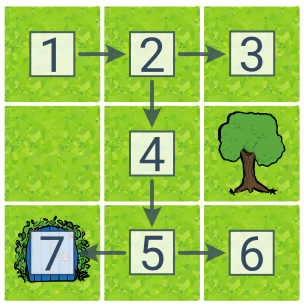
V této ukázce předpokládáme, že DFS zkouší akce po směru hodinových ručiček (doprava–dolů–doleva–nahoru). Čísla u stavů popisují pořadí objevení. Cíl byl nalezen v 7. kroce a nalezený plán má 4 kroky (doprava–dolů–dolů–doleva).
Prohledávání do šířky (BFS, angl. Breadth First Search) prohledává stavy po vrstvách podle počtu akcí od počátečního stavu. To sice zvyšuje paměťovou složitost (je potřeba si pamatovat více stavů), ale vede k nalezení nejkratšího řešení.
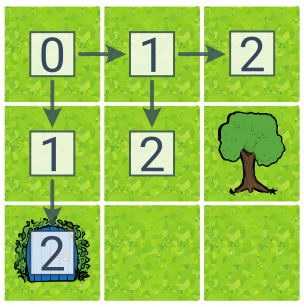
Čísla u stavů v ukázce BFS zachycují vzdálenosti od počátečního stavu, což odpovídá pořadí procházení „po vrstvách“. BFS našlo optimální řešení řešení (dolů–dolů) po prozkoumání 6 stavů.
Prohledávání podle ceny (UCS, angl. Uniform Cost Search) je variací BFS, které umožňuje nalézt nejlevnější řešení, i když mají akce různou cenu. K rozšíření vybíráme plán s nejnižší cenou.
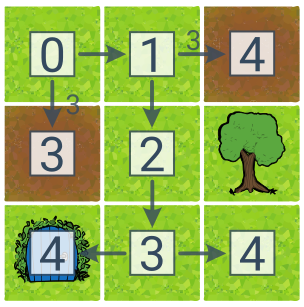
Pro ukázku UCS jsme přidali do plánku dvě hnědé bažiny s třikrát vyšší cenou přechodů. Čísla ve čtverečcích zde zachycují cenu plánu. V tomto případě je nejlevnější řešení (s cenou 4) doprava–dolů–dolů–doleva a UCS ho nalezne. (BFS by vrátilo řešení dolů–dolů s cenou 6.)
Algoritmus stromového prohledávání
Při stromovém prohledávání si udržujeme množinu stavů, které chceme v budoucnu prozkoumat, tzv. okraj. V každém kroku jeden stav z okraje odebereme a do okraje zařadíme jeho následníky (tj. stavy, do kterých se lze dostat z odebíraného stavu jednou akcí). Obecné schéma stromového prohledávání je následovné:
- Zařaď do okraje počáteční stav.
- Opakuj následující kroky, dokud nenajdeš cíl.
- Odeber jeden stav z okraje. Pokud je cílový, skonči.
- Jinak ho expanduj, tj. zařaď do okraje jeho následníky.
- Pokud se vyprázdnil okraj, tak cesta do cíle neexistuje.
Zmíněné varianty stromového prohledávání se liší tím, jakou strategii využívají k výběru stavu z okraje (krok 3), tj. jak implementují okraj. Prohledávání do hloubky (DFS) používá zásobník (odebíráme naposledy vložený stav), prohledávání do šířky (BFS) frontu (odebíráme nejdříve vložený stav) a prohledávání podle ceny (UCS) prioritní frontu (odebíráme stav s nejnižší cenou zatím nejlevnějšího plánu vedoucího do daného stavu).
Abychom se vyhnuli opakovanému prozkoumávání stejných stavů, můžeme si navíc udržovat množinu již prozkoumaných stavů a ty znova neexpandovat. Toto rozšíření se někdy označuje jako obecné grafové prohledávání, aby se odlišilo od stromového prohledávání bez kontroly dříve prozkoumaných stavů. Nevýhodou je zvýšení paměťové náročnosti.
Informované prohledávání
Prohledávání lze urychlit pomocí heuristik poskytujících odhad vzdálenosti do cíle. Taková informace je závislá na konkrétní úloze. Prohledávání využívající heuristiky označujeme jako informované prohledávání. (Algoritmy v předchozích sekcích označujeme naopak jako „neinformované“.)
Hladové prohledávání se řídí pouze hodnotou heuristiky a vybírá vždy akci, která nás dostane nejblíže cíli. Pokud hrozí slepé uličky, je potřeba hladový přístup zkombinovat se stromovým prohledáváním (jde tedy o tzv. hladové stromové prohledávání) – jako další stav vybíráme ten s nejnižším odhadem ceny podle heuristiky. Hladové prohledávání je velmi rychlé, negarantuje však nalezení optimálního řešení.
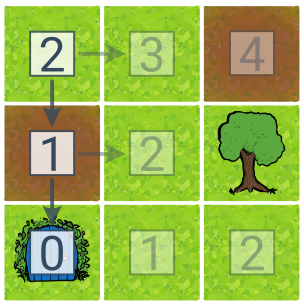
V této ukázce stromového hladového prohledávání odpovídají čísla u stavů heuristickému odhadu ceny do cíle. Heuristikou je vzdálenost od cíle spočítaná jako součet odchylek sloupce a řádku. Algoritmus našel cestu do cíle během dvou kroků, nikoliv však cestu nejlevnější.
A* prohledávání („A star“) kombinuje prohledávání podle ceny (UCS) s heuristikou. Jde o stromové prohledávání, kdy jako další stav vybíráme takový, který má nejnižší součet dosavadní ceny a heuristického odhadu zbývající ceny do cíle. Pokud je heuristika optimistická (poskytuje dolní odhad skutečné ceny), pak A* nelezne optimální řešení a nalezne ho tím rychleji, čím těsnější odhady skutečné ceny heuristika poskytuje.
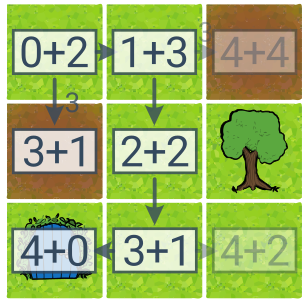
Součet u stavů popisuje prioritu pro A*: [dosavadní cena] + [odhad zbývající ceny]. A* našlo optimální řešení a prozkoumalo přitom méně stavů než UCS (6 místo 8).
Splňování podmínek
Mnoho úloh umělé inteligence lze formulovat jako splňování podmínek. Úloha splňování podmínek je zadaná sadou proměnných, jejich doménami (možné hodnoty) a sadou podmínek na kombinace hodnot proměnných. Ohodnocení (přiřazení hodnot některým proměnným) je řešením úlohy, pokud je úplné (přiřazuje hodnotu všem proměnným) a konzistentní (neporušuje žádnou podmínku). Někdy je navíc zadána účelová funkce určující hodnotu řešení, kterou chceme optimalizovat.
Oblast informatiky zabývající se touto úlohou se označuje jako programování s omezujícími podmínkami. Splňování podmínek je podstatou mnohých logických úloh (např. problém 8 dam, Einsteinova hádanka, algebrogram). Na Umíme si můžete vyzkoušet sudoku, ploty a binární křížovku. Praktickou aplikací je třeba sestavování konfigurací produktu splňující zadaná omezení nebo tvorba rozvrhů (školní rozvrhy, jízdní řády, logistika výroby, rozpis zápasů na turnaji).
Problém 8 dam
Úkol rozestavit na šachovnici 8 dam tak, aby se žádné dvě vzájemně neohrožovaly. (Dáma se může pohybovat o libovolný počet polí vodorovně, svisle i diagonálně.) Úlohu lze zobecnit na „problém N dam“, které máme umístit na šachovnici velikosti N×N.
Einsteinova hádanka
Úkol odvodit vlastnosti několika objektů na základě omezených informací. Nejznámější zadání popisuje pět domů, které stojí vedle sebe, liší se barvou, národností majitelů, jejich oblíbeným nápojem, značkou cigaret a domácím mazlíčkem. K dispozici máme 15 informací typu „Angličan žije v červeném domě.“
Algebrogram
Úkol nahradit písmena za různé číslice tak, aby byl splněný zadaný vzorec. Příklad: SEND + MORE = MONEY.
Řešení úloh splňování podmínek
Jakmile nějaký problém namodelujeme jako úlohu splňování podmínek, lze využít obecné postupy pro jejich řešení. Naivní zkoušení všech možných ohodnocení (generuj a testuj) většinou bude příliš pomalé, protože počet možných ohodnocení roste exponenciálně k počtu proměnných. K řešení se proto typicky používá postupné budování řešení s propagací omezení, nebo postupné zlepšování úplného ohodnocení.
Které problémy jsou těžké?
Obtížnost úloh s omezujícími podmínkami závisí na poměru počtu omezení ku počtu proměnných. Pokud je tento poměr hodně vysoký, nebo naopak hodně nízký, pak bude snadné nějaké řešení nalézt (nebo zjistit, že žádné neexistuje). Představte si sudoku, které má téměř všechna pole vyplněná (je snadné určit zbývající čísla), nebo naopak má vyplněných polí jen pár (existuje mnoho různých řešení).
Postupné budování řešení
Tento přístup spočívá v systematickém zkoušení možných ohodnocení. Na rozdíl od „generuj a testuj“ však ohodnocujeme jednotlivé proměnné postupně a průběžně kontrolujeme, zda nedošlo k porušení některé podmínky. Pokud ano, vyzkoušíme jinou hodnotu. Pokud jsme už vyzkoušeli všechny možné hodnoty dané proměnné, vracíme se k předchozí proměnné a zkusíme změnit její hodnotu (těchto návratů může být libovolné množství). Tomuto algoritmu se říká prohledávání s návratem (backtracking).
Splňování podmínek vs. plánování
Úlohu splňování podmínek lze formulovat jako úlohu plánování, v němž stavy představují různá ohodnocení proměnných, počáteční stav je prázdné ohodnocení, akce odpovídají přiřazení hodnoty do jedné proměnné a cílovým stavem je úplné konzistentní ohodnocení. (Všechna řešení jsou tedy ve stejné hloubce dané počtem proměnných.)
Rozdíl od obecné plánovací úlohy spočívá v tom, že stavy a cíl mají vnitřní strukturu – stav se skládá z hodnot více proměnných, cíl se skládá z více podmínek. Díky této vnitřní struktuře lze úlohy splňování podmínek řešit výrazně efektivněji než obecnými technikami prohledávání stavového prostoru. Můžeme například poznat, že jsme ve slepé větvi, když není některá podmínka splněná. Druhý rozdíl spočívá v tom, že nás nezajímá plán (posloupnost akcí vedoucí do cíle, např. pořadí vyplňování políček sudoku), ale cílový stav (ohodnocení proměnných, např. vyplněné sudoku).
Prohledávání s návratem (backtracking) je v podstatě prohledávání do hloubky (DFS) s včasnou kontrolou porušení podmínek. (Druhým rozdílem je, že nezáleží na pořadí akcí – výsledné řešení je stejné, ať jsme nejdříve přiřadili hodnotu proměnné A nebo B. Při prohledávání s návratem proto stačí prohledávat pouze jedno pořadí proměnných.)
Velký vliv na rychlost prohledávání s návratem mají heuristiky pro výběr proměnné a její hodnoty. Pro výběr proměnné se využívá princip brzkého neúspěchu: vybíráme proměnnou, pro kterou je těžké najít hodnotu (např. tu s nejmenší doménou). Naopak, pro výběr hodnot je vhodnější princip brzkého úspěchu, tedy výběr hodnoty, která by nejspíše mohla být součástí řešení (např. tu, která způsobí nejmenší filtraci domén). Důvod k opačným principům pro výběr proměnné a hodnoty spočívá v tom, že proměnné musíme nakonec projít všechny, ale hodnoty nikoliv.
Prohledávání s návratem lze dále výrazně urychlit propagací omezení. Po každé volbě hodnoty provedeme filtrování domén, čímž se zmenší počet hodnot budoucích proměnných, které bude potřeba zkoušet.
Propagace omezení
Z domén proměnných můžeme bezpečně odstranit hodnoty, pro které nelze splnit některou podmínku (neexistují hodnoty ostatních proměnných v podmínce, pro které by podmínka platila). (Sudoku: Když už je někde umístěná číslice, můžeme ji vyškrtnout z domén všech políček na stejném řádku, sloupci a čtverci.) Pokud zbývá v doméně proměnné jediná možná hodnota, známe část řešení.
Podmínky můžeme kontrolovat opakovaně, dokud se nám daří nějaké hodnoty vyškrtávat. V ojedinělých případech (lehká sudoku) lze opakovaným filtrováním získat celé řešení, častěji však pouze úlohu zjednodušíme a pak je potřeba zkoušet různé možné hodnoty (proto se propagace omezení využívá typicky v kombinaci s prohledáváním s návratem).
Výraznějšího filtrování dosáhneme, když budeme kontrolovat současně splnění více podmínek naráz, nikoliv vždy jen jedné (to ale zvyšuje výpočetní náročnost).
Postupné zlepšování
Alternativou k postupnému budování řešení je začít s kompletním ohodnocením (klidně náhodným) a to postupně vylepšovat drobnými úpravami. Ohodnocení je tedy celou dobu úplné, ale nikoliv konzistentní. Vylepšení je taková změna ohodnocení, která zmenší počet porušených podmínek. Algoritmy postupného zlepšování lze rozdělit do dvou kategorií podle toho, jestli pracují v jeden moment s jediným ohodnocením (lokální prohledávání) nebo s více naráz (prohledávání s populací).
Lokální prohledávání pracuje s jedním ohodnocením, které postupně vylepšuje. Množina všech ohodnocení, které se od toho současného lidí jednou změnou, nazýváme okolí. Metoda největšího stoupání (horolezecký algoritmus) vybírá z okolí to ohodnocení, které vede k nejvýraznějšímu zlepšení. Tímto postupem se rychle dostaneme do lokálního optima, kdy všechny okolní stavy jsou horší. Lokální optimum však nemusí být optimemem globálním, zejména tedy nemusí jít o přípustné řešení.
Proto je potřeba využít meta-heuristiky, které vnáší do prohledávání prvek náhodnosti a tedy šanci uniknout lokálnímu optimu. Příkladem meta-heuristiky je simulované žíhání, při kterém z okolí vybíráme náhodně; pokud je nové ohodnocení zlepšující, tak ho přijmeme, pokud není zlepšující, tak ho přijmeme s určitou pravděpodobností, která se postupně snižuje. Jednoduchou meta-heuristikou je také opakované spouštění lokálního prohledávání z různých náhodných počátečních ohodnocení.
Při prohledávání s populací vylepšujeme mnoho ohodnocení naráz. To umožňuje vybírat nejlepší ohodnocení z aktuální populace a případně různá ohodnocení kombinovat. Příkladem jsou genetické algoritmy inspirované fungováním evoluce. Ohodnocení pokračující do další generace jsou vybírána podle jejich kvality, kombinována („křížení“) a případně drobně náhodně měněna („mutace“). Do této kategorie patří také další algoritmy inspirované přírodou, které využívají velké množství interagujících agentů reprezentujících úplná ohodnocení. (Například při „optimalizaci mravenčí kolonií“ má každý mravenec přidružené ohodnocení a podle jeho kvality vydává různě silnou feromonovou stopu – čím je ohodnocení lepší, tím spíš budou další mravenci zkoušet podobná ohodnocení.)
Optimalizace
Optimalizace znamená hledání nejlepšího řešení. Hledáme hodnoty optimalizovaných proměnných, při kterých je zadaná účelová funkce nejvyšší (maximum), nebo nejnižší (minimum). Optimalizace se využívá například při plánování výroby, rozvrhování dopravy, návrhu telekomunikačních sítí a trénování modelů ve strojovém učení.
Optimalizační úlohy
Maximalizační a minimalizační úlohy lze řešit stejnými technikami, každý maximalizační problém lze totiž převést na minimalizační úlohu (a naopak) převrácením účelové funkce. Různé techniky se však liší v tom, zda je lze použít v diskrétním či spojitém prostoru (ve spojitém prostoru můžou proměnné nabývat libovolných reálných čísel) a zda může problém obsahovat omezující podmínky.
Příklady optimalizačních úloh
Problem batohu. Vybrat kombinaci předmětů, která se vejde do batohu omezené kapacity, aby celková hodnota byla co nejvyšší.
Problém obchodního cestujícího. Najít nejkratší cestu, která projde všemi zadanými městy a vrátí se do výchozího bodu.
Rozvrhování. Najít optimální (nejkratší, nejlevnější) rozvržení aktivit v čase s ohledem na dané zdroje a omezení.
Strojové učení. Zvolit parametry modelu (např. váhy neuronové sítě) minimalizující chybu predikcí na trénovacích datech.
Problém čokoládových sušenek. Najít recept na co nejlepší čokoládové sušenky.
Systematické prohledávání
Nejjednodušším přístupem je zkoušení všech možností (hrubá síla). Ve spojitém prostoru je možností nekonečně mnoho, lze však systematicky vyzkoušet všechny kombinace hodnot s určitým rozlišením (mřížkové prohledávání). Tento přístup je použitelný jen pro velmi malé problémy, protože počet možností roste exponenciálně s počtem proměnných. Při řešení problému batohu můžeme každý předmět buď vzít, nebo nevzít, existuje tedy 2^n možných kombinací předmětů.
Efektivnější je přiřazovat hodnoty proměnným postupně a průběžně odhadovat nejlepší možnou hodnotu řešení s daným částečným přiřazením. Když je tato mez horší než zatím nejlepší nalezené řešení, můžeme celou větev přeskočit a být si jistí, že jsme přitom nepřeskočili optimální řešení. Tato varianta stromového prohledávání se nazývá metoda větví a mezí (angl. branch and bound). Pro výběr dalšího stavu k průzkumu lze využít hladové kritérium – stav s nejlepší hodnotou meze (nebo jinou strategii stromového prohledávání stavového prostoru).
Hladové a náhodné prohledávání
Systematické prohledávání garantuje nalezení globálního optima, velmi často je však příliš pomalé pro praktické problémy. Pro urychlení je potřeba vzdát se požadavku na optimální řešení, pro většinu praktických problémů naštěstí stačí řešení, které je „dostatečně dobré“. K urychlení lze pak využít hladovost a náhodnost.
Hladové prohledávání vybírá pro každou proměnnou hodnotu, která se zdá zatím nejlepší a zpětně se k těmto rozhodnutím nevrací. Při řešení problému batohu bychom mohli brát postupně předměty s nejvyšším poměrem cena/váha, dokud se do batohu vejdou. Hladové prohledávání je sice velmi rychlé, ale nalezené řešení může být hodně špatné. Mezi extrémy hladového prohledávání (zkoušíme jedinou cestu) a systematického stromového prohledávání (zkoušíme všechny cesty) existuje paprskové prohledávání (zkouší fixní počet cest). Paprskové prohledávání ponechává na každé úrovni stromu pouze fixní počet nejlepších stavů a ostatní zahazuje.
Náhodné prohledávání zkoumá náhodně vybraná řešení (místo všech možných). Existují složitější techniky, které postupně zvyšují pravděpodobnost výběru řešení v nadějných oblastech – snaží se vyvažovat průzkum zatím neprobádaných oblastí (náhodnost) a zužitkování informací o více prozkoumaných oblastech (hladovost). Tento kompromis mezi průzkumem a zužitkováním (angl. exploration-exploitation tradeoff) je obecným principem využívaným v mnoha optimalizačních algoritmech.
Hladovost i náhodnost se používají také v rámci metod postupného vylepšování zmíněných v následujících sekcích.
Lokální prohledávání
Alternativou k postupnému budování řešení je začít s libovolným řešením, a to postupně vylepšovat drobnými změnami. Tento přístup se nazývá lokální prohledávání. Množinu blízkých řešení, které se od toho aktuální liší jedinou změnou, nazýváme okolí. (Při řešení problému batohu by okolí mohlo zahrnovat například ty kombinace, které se liší nejvýše jedním přidaným a jedním odebraným předmětem.) Existují různé heuristiky pro výběr dalšího řešení z okolí. Horolezecký algoritmus vybírá některé zlepšující řešení, případně nejlepší řešení z okolí (tato varianta horolezeckého algoritmu se označuje jako metoda největšího stoupání).
S využitím těchto hladových heuristik dorazíme rychle do lokálního optima, tedy řešení, které je nejlepší ve svém okolí, nemusí však jít o globální optimum. Šanci na nalezení globálního optima lze zvýšit využití náhodnosti. Simulované žíhání vybírá z okolí náhodně; pokud je nové řešení zlepšující, tak ho přijmeme, pokud není zlepšující, tak ho přijmeme s určitou pravděpodobností, která se postupně snižuje.
Obdoba lokálního prohledávání ve spojitém prostoru je gradientní sestup. Ve spojitém prostoru lze často vypočítat směr, ve kterém účelová funkce nejrychleji klesá nebo stoupá (tzv. gradient), není pak potřeba testovat různá řešení v okolí. Gradientní sestup se běžně využívá ve strojovém učení, např. pro optimalizaci vah neuronové sítě.
Prohledávání s populací
Při prohledávání s populací vylepšujeme mnoho řešení naráz. To umožňuje vybírat nejlepší řešení z aktuální populace a případně různá řešení kombinovat. Příkladem jsou genetické algoritmy inspirované fungováním evoluce. Řešení pokračující do další generace jsou vybírána podle jejich kvality (hodnoty účelové funkce), kombinována („křížení“) a případně drobně náhodně měněna („mutace“).
Do této kategorie patří také algoritmy inteligence hejna inspirované skupinovým chováním nějakého druhu (typicky při hledání potravy). Tyto algoritmy využívají velké množství jednoduchých agentů reprezentujících různá řešení, kteří spolu nepřímo interagují skrze společnou paměť. Například při optimalizaci mravenčí kolonií má každý mravenec přidružené řešení a na své trase vydává feromonovou stopu, která je tím silnější, čím lepší řešení. Všechny feromonové stopy dohromady tvoří společnou pamětí, podle které se pak řídí další mravenci (preferují cesty s výraznější feromonovou stopou, které se v minulosti osvědčily).
Princip strojového učení
Umělá inteligence často využívá učení z dat, tzv. strojové učení. Vstupem strojového učení je velké množství dat (dataset), výstupem je naučený model pro řešení požadovaného úkolu. Máme-li dostatek dat popisujících vzhled a chování příšerek, můžeme naučit model, který bude pro nové příšerky odhadovat, zda jsou hodné, na základě jejich vzhledu.
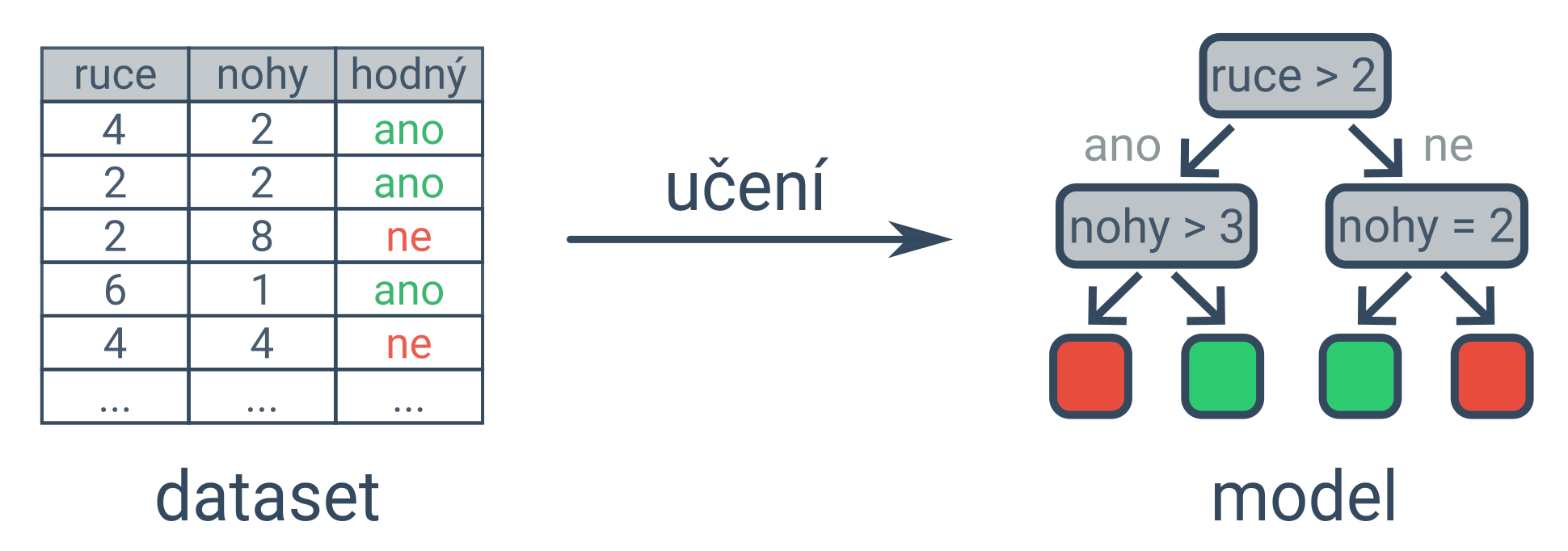
Klíčovou ingrediencí pro strojové učení je velké množství dat. Jednotlivé příklady jsou typicky poměrně jednoduché (např. jedna fotka), ale je jich hodně (někdy i miliony). Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data (memorizace), musí být schopen určovat správný výstup i pro příklady nové (zobecňování, generalizace).
Příkladem modelu je rozhodovací strom (na obrázku výše) nebo neuronová síť (model volně inspirovaný sítí neuronů v mozku). Strojové učení může v závislosti na množství dat trvat vteřiny i celé dny, pro urychlení se proto někdy využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit).
Strojové učení lze vnímat jako alternativu ke klasickému programování, při kterém programátor zapisuje posloupnost přesných instrukcí (např. if-then pravidla nebo heuristika na základě zkušenosti). Strojové učení bude vhodným přístupem zejména tehdy, když není jasné, jak by takový klasický program měl vypadat a přitom lze sehnat rozsáhlé množství příkladů (např. detekce spamu). Strojové učení spíše nebude vhodným přístupem pro kritická rozhodnutí, kde není tolerovatelná žádná chyba a potřebujeme vysokou předvídatelnost a transparentnost chování (např. bankovní převod).
Aplikace strojového učení (příklady)
- detekce spamu
- diagnóza nemoci
- rozpoznání hlasu
- překlad textů
- doporučování filmů
- řízení auta
- generování obrázků podle popisu
Základy strojového učení
Strojové učení je podoblast umělé inteligence zabývající se tvorbou programů, které se učí z dat. Strojové učení souvisí s tématem práce s daty, zejména s jejich sběrem a evidencí. V rámci základního přehledu strojového učení najdete na Umíme následující témata:
- princip strojového učení – co to je strojové učení, v čem spočívá rozdíl oproti klasickému programování, na co se strojové učení hodí
- typy úloh, které lze pomocí strojového učení řešit (např. klasifikace, regrese, shlukování)
- postup řešení těchto úloh (např. učení s učitelem a bez učitele, neuronové sítě a jiné modely)
- vyhodnocení naučených modelů (rozlišení mezi generalizací a pouhou memorizací, rozpoznání podučení a přeučení, srovnání kvality různých modelů)
- zkreslení (předpojatost) ve strojovém učení (co to je, jak rozpoznat a co se s tím dá dělat)
- pojmy často používané v textech o strojovém učení
Princip strojového učení
Umělá inteligence často využívá učení z dat, tzv. strojové učení. Vstupem strojového učení je velké množství dat (dataset), výstupem je naučený model pro řešení požadovaného úkolu. Máme-li dostatek dat popisujících vzhled a chování příšerek, můžeme naučit model, který bude pro nové příšerky odhadovat, zda jsou hodné, na základě jejich vzhledu.
Klíčovou ingrediencí pro strojové učení je velké množství dat. Jednotlivé příklady jsou typicky poměrně jednoduché (např. jedna fotka), ale je jich hodně (někdy i miliony). Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data (memorizace), musí být schopen určovat správný výstup i pro příklady nové (zobecňování, generalizace).
Příkladem modelu je rozhodovací strom (na obrázku výše) nebo neuronová síť (model volně inspirovaný sítí neuronů v mozku). Strojové učení může v závislosti na množství dat trvat vteřiny i celé dny, pro urychlení se proto někdy využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit).
Strojové učení lze vnímat jako alternativu ke klasickému programování, při kterém programátor zapisuje posloupnost přesných instrukcí (např. if-then pravidla nebo heuristika na základě zkušenosti). Strojové učení bude vhodným přístupem zejména tehdy, když není jasné, jak by takový klasický program měl vypadat a přitom lze sehnat rozsáhlé množství příkladů (např. detekce spamu). Strojové učení spíše nebude vhodným přístupem pro kritická rozhodnutí, kde není tolerovatelná žádná chyba a potřebujeme vysokou předvídatelnost a transparentnost chování (např. bankovní převod).
Aplikace strojového učení (příklady)
- detekce spamu
- diagnóza nemoci
- rozpoznání hlasu
- překlad textů
- doporučování filmů
- řízení auta
- generování obrázků podle popisu
Úlohy strojového učení
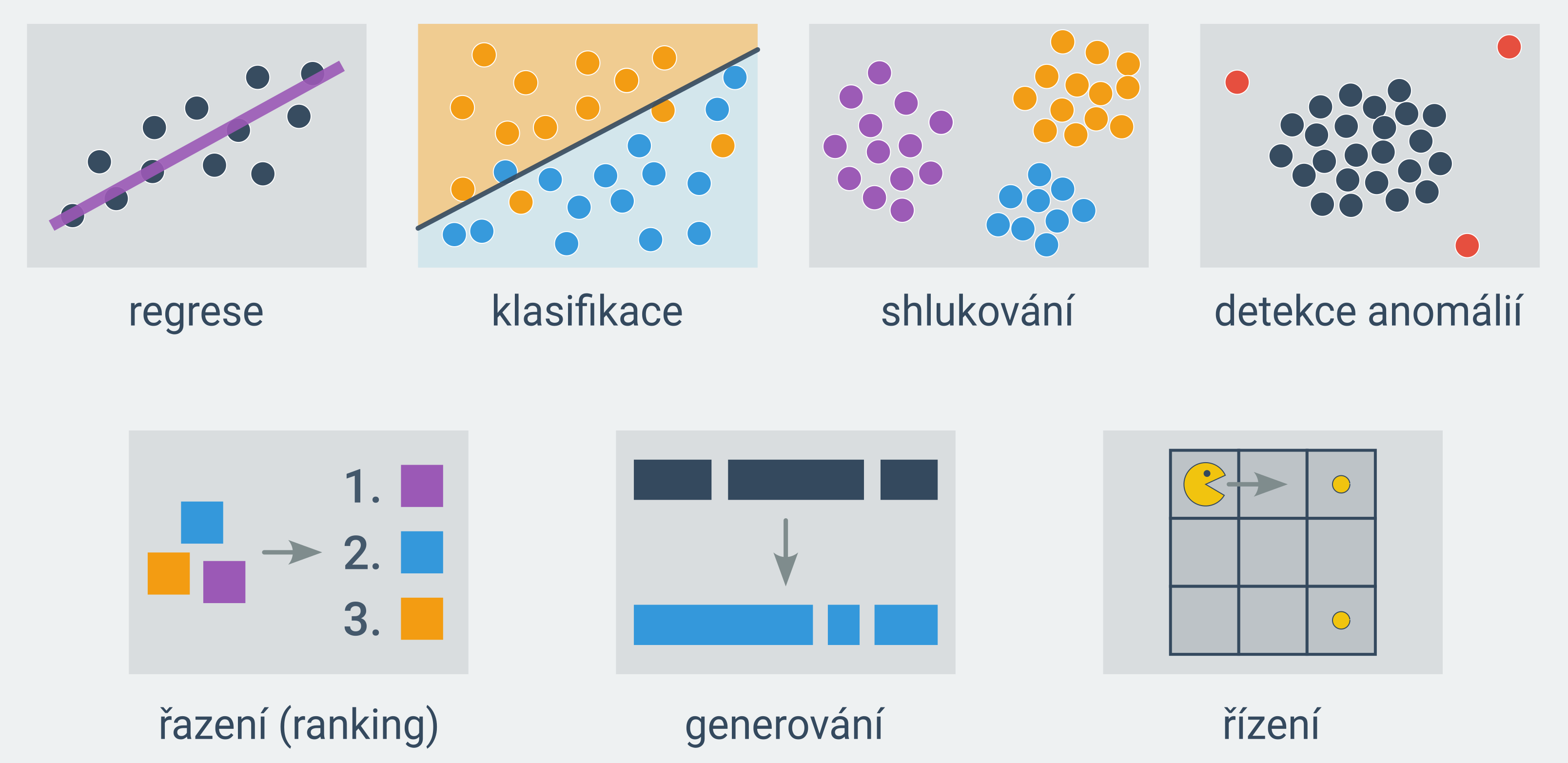
Pomocí strojového učení lze řešit rozličné typy úloh, mezi ty nejčastější patří:
regrese = odhad číselné hodnoty (Jak bude daný uživatel hodnotit daný film? Jaká bude teplota zítra odpoledne?)
klasifikace = určování příslušnosti k jedné z několika předem daných kategorií (Je daný e-mail spam? Která kytka je na fotce?)
shlukování = rozdělení příkladů do skupin s podobnými vlastnostmi (Které zprávy řeší podobné téma? Které chemické látky se chovají podobně?)
hledání anomálií = upozornění na podezřelé příklady, které se výrazně liší od zbytku dat (detekce případů, kdy bankovní účet nevyužívá jeho skutečný majitel)
řazení (ranking) = uspořádání příkladů (seřazení výsledků vyhledávání, seřazení doporučených videí)
generování = vytvoření textu nebo obrázku na základě jiného textu nebo obrázku (odpovídání na otázky, strojový překlad, vygenerování popsaného obrázku)
řízení = hledání strategie pro optimální rozhodování (hraní šachů a podobných her, řízení autonomního auta)
Postup strojového učení
Využití strojového učení zahrnuje následující fáze:
příprava datasetu – může zahrnovat sběr a anotování dat (doplnění požadovaného výstupu)
trénování modelu – určení vhodných hodnot parametrů modelu
testování modelu – na nových datech, které model neviděl během trénování
nasazení modelu – tedy jeho použití pro zadaný úkol
Typy přístupů
Přístupy ke strojovému učení lze rozlišit podle povahy signálu o požadovaném výstupu modelu:
učení s učitelem (angl. supervised learning) – požadovaný výstup je součástí trénovacích dat (např. zda je příšerka hodná, zda je e-mail spam). Doplňování požadovaných výstupů se říká anotování dat. Datům s požadovaným výstupem se pak někdy říká označkovaná data.
učení bez učitele (angl. unsupervised learning) – trénovací data neobsahují požadovaný výstup, úkolem je najít vzory v datech (např. podobné příšerky, podobné zprávy)
posilované učení (někdy též zpětnovazební učení, angl. reinforcement learning) = učení skrze interakci s prostředím zahrnující zpětnou vazbu na provedené akce (např. výhra v šachu, řízení auta bez nehod)
Různé přístupy jsou vhodné na různé typy úloh. Učením s učitelem se typicky řeší regrese, klasifikace, řazení a generování, učením bez učitele shlukování a hledání anomálií, posilovaným učením řízení. Často se však přístupy kombinují.
Modely
Pro řešení úloh strojového učení existuje celá řada modelů. Příkladem jsou lineární modely, rozhodovací stromy a neuronové sítě:
Lineární modely určují výstup na základě váženého součtu atributů. Pokud je 2 × počet rukou + 3 × počet nohou menší než 18, pak je příšerka hodná.
Rozhodovací stromy určují výstup na základě podmínek. Pokud má příšerka (více jak dvě ruce a nejvýše tři nohy) nebo (nejvýše dvě ruce a právě dvě nohy), pak je hodná.
Neuronové sítě se skládají z mnoha propojených neuronů, kde každý neuron počítá relativně jednoduchou funkci (podobně jako lineární model). Protože je ale neuronů hodně, je výsledná funkce určená neuronovou sítí složitá. Neurony jsou typicky uspořádané do několika vrstev. Učení neuronové sítě s mnoha vrstvami se označuje jako hluboké učení (angl. deep learning).
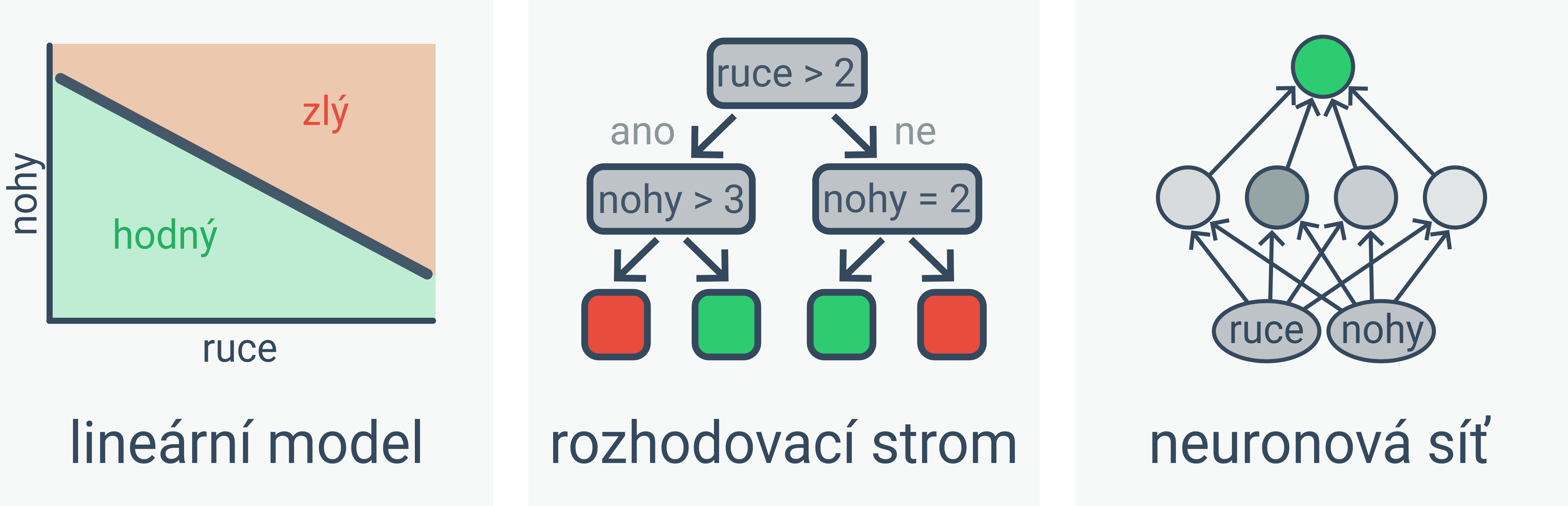
Volba vhodného modelu závisí například na množství dat a požadované interpretovatelnosti výstupů modelu. Neuronové sítě a jiné modely s mnoha parametry se umí naučit velmi složité funkce, ale vyžadují hodně dat a jsou hůře interpretovatelné než lineární modely a rozhodovací stromy.
Učící algoritmy
Učící algoritmus hledá strukturu nebo parametry modelu tak, aby minimalizoval zadanou chybu. Příkladem učícího algoritmu, který se využívá např. pro lineární modely a neuronové sítě, je gradientní sestup (angl. gradient descent). Při gradientním sestupu začneme s náhodnými hodnotami parametrů a ty pak opakovaně upravujeme tak, abychom zmenšili chybu modelu. Jiný učící algoritmus se používá pro budování rozhodovacích stromů: strom postupně zvětšujeme přidáváním rozhodovacích uzlů s podmínkami, které co nejlépe rozdělují příklady.
Příklad učení lineárního klasifikátoru příšerek
Parametry lineárního modelu jsou (a) váha pro počet rukou, (b) váha pro počet nohou a (c) hranice, při které je ještě příšerka klasifikovaná jako hodná: a \cdot \text{[počet rukou]} + b \cdot \text{[počet nohou]} < c
Například pro hodnoty parametrů a = 2, b = 4, c = 20 bude model klasifikovat příšerku jako hodnou tehdy, když 2 \cdot \text{[počet rukou]} + 4 \cdot \text{[počet nohou]} < 20.
Různá nastavení těchto parametrů vedou na různý počet chybně klasifikovaných příšerek. Řekněme, že při hodnotách parametrů a = 2, b = 4, c = 20 model klasifikuje chybně 20 % příšerek. Gradientní sestup by mohl parametry upravit na a = 2, b = 3, c = 18 a snížit tak chybu třeba na 15 %. Gradientní sestup by opakovaně prováděl takovéto drobné úpravy parametrů (spíše ještě drobnější).
Směr změny parametrů, který co nejvíce sníží chybu, závisí na konkrétní chybové funkci a pro mnohé chybové funkce lze tento směr (tzv. gradient) spočítat.
Vyhodnocení strojového učení
Aby byl model užitečný, nestačí aby si zapamatoval trénovací data, musí být schopen určovat správný výstup i pro příklady nové, tedy generalizovat. Kvalitu modelu je proto potřeba vyhodnotit na datech, která model neviděl během učení, jinak bude vyhodnocení neoprávněně optimistické. Situaci, kdy si model zapamatuje přesné odpovědi pro trénovací data, ale není schopen generalizovat, nazýváme přeučení (někdy též přetrénování, angl. overfitting). Situaci, kdy je zvolený model příliš jednoduchý na danou úlohu, takže má vysokou chybu i na trénovacích datech, nazýváme podučení (někdy též podtrénování, angl. underfitting).

Složitější modely jsou typicky náchylnější k přeučení, protože se umí naučit libovolný šum v datech. Pokud jsou dva modely podobně správné na datech, která máme k dispozici, tak pro nová data bude proto pravděpodobněji lépe generalizovat ten jednodušší z nich. Jde o případ obecného principu zvaného Occamova břitva, který říká, že existuje-li více různých vysvětlení, je lépe upřednostňovat to jednodušší z nich.
Kvalitu modelů lze kvantifikovat pomocí různých metrik. Pro vyhodnocení regresních modelů se často používá střední kvadratická chyba (angl. mean squared error), což je průměrná druhá mocnina odchylky mezi predikovanou a skutečnou hodnotou. Pro vyhodnocení klasifikačních modelů se používá například správnost (angl. accuracy, podíl správných odpovědí), přesnost (angl. precision, kolik ze všech označených příkladů je pozitivních) a pokrytí (angl. recall, kolik ze všech pozitivních příkladů model detekoval).
Užitečnou vizualizací je matice záměn (angl. confusion matrix), která zobrazuje, kolik kterých kategorií bylo jak klasifikováno. Následující matice kompaktně zachycuje chování modelu pro predikci nemoci (P – pozitivní, N – negativní), kdy model v 9 případech správně predikoval pozitivní výsledek, v 87 správně predikoval negativní výsledek, v 1 případě chybně predikoval pozitivní výsledek a ve 3 případech chybně predikoval negativní výsledek.

Vždy je vhodné problém nejprve zkusit řešit pomocí jednoduchého základního modelu (angl. baseline), což může být například průměrná hodnota (pro regresi) nebo nejčastější kategorie (pro klasifikaci). Srovnání metrik složitějšího modelu se základním modelem umožňuje hodnoty metrik lépe interpretovat.
Zkreslení strojového učení
Zkreslení (někdy též předpojatost, podjatost, zaujatost, angl. bias) znamená systematickou chybu, která vede k neférovým důsledkům pro různé skupiny. Nemusí jít o skupiny lidí, pojem zkreslení se používá i pro situaci, kdy model např. výrazně častěji predikuje jednu kategorii (např. hrušky), přestože se jiné kategorie (např. jablka) vyskytují podobně často.
Zkreslení modelu může podporovat předsudky (model predikující studijní výsledky v určitém oboru využívající informaci o pohlaví) a vést k diskriminaci (pokud by byl tento model použit pro rozhodování o přijetí na univerzitu).
Zkreslení modelu je většinou způsobeno zkreslenými daty, model se totiž naučí pouze to, co vidí v datech. K výběrovému zkreslení dochází, pokud data nereprezentují adekvátně všechny typy případů. Pokud bychom trénovali rozpoznávání bot pouze na pánských botech, model nebude rozpoznávat dámské boty. Ke zkreslení odpovědí může dojít např. kvůli předsudkům anotujících osob, nebo kvůli neochotě respondentů sdělit pravdu. V dotazníkových šetřeních lidé často upravují svoje odpovědi o sobě podle společenských očekávání.
Zkreslení může být náročné odhalit, protože na rozdíl od přeučení se většinou neprojeví nižší úspěšností na testovacích datech. Při běžném postupu totiž data pro testování a učení pocházejí z jednoho zdroje, takže obsahují tatáž zkreslení.
Abychom snížili riziko zkreslení, je vhodné důsledně kontrolovat kvalitu dat. Měli bychom například ověřit, že posbíraná data obsahují všechny typy případů a že jsou jednotlivé kategorie zastoupeny podobným množstvím příkladů, podobné kvality a v podobných kontextech. Při anotování dat je vhodné, aby ho prováděli lidé z různých skupin (např. muži i ženy). Je také užitečné vyhodnocovat chování modelu pro různé podskupiny dat (např. pro muže a ženy, různé věkové skupiny, menšiny) a průběžně monitorovat chování modelu i po nasazení.
Strojové učení: pojmy
Zde uvádíme přehled pojmů, se kterými se můžete často potkat v textech o strojovém učení. Mnoho z nich zatím nemá ustálené české překlady, proto se i v českých textech často používají anglické výrazy (níže uvedené kurzivou v závorce). Podrobnější vysvětlení jednotlivých pojmů najdete v dílčích tématech strojového učení.
| pojem | popis |
|---|---|
| strojové učení | učení programů na základě dat |
| model | mapování vstupů na výstupy (řešení úlohy strojového učení) |
| datová sada (dataset) | data pro trénování modelu |
| příklad (example) | jeden kompletní vstup pro model (řádek datasetu) |
| atribut (feature) | informace o příkladech použitá modelem (sloupec datasetu) |
| štítek (label) | správný výstup pro daný příklad |
| anotování dat | přiřazování správných výstupů (štítků) |
| označkovaná data | data s požadovaným výstupem (štítkem) |
| predikce | předpověď, odhad (výstup modelu) |
| inference | vytvoření odhadů natrénovaným modelem |
| učení s učitelem (supervised learning) | přístup ke strojovému učení využívající označkovaná data |
| učení bez učitele (unsupervised learning) | přístup ke strojovému učení využívající neoznačkovaná data |
| učení s částečným dohledem (semi-supervised learning) | přístup ke strojovému učení využívající označkovaná i neoznačkovaná data |
| posilované učení, zpětnovazební učení (reinforcement learning) | učení skrze interakci s prostředím zahrnující zpětnou vazbu na provedené akce |
| klasifikace | úloha určit příslušnost příkladu k jedné z několika předem daných kategorií (např. žánr knížky) |
| regrese | úloha určit číselnou hodnotu pro daný příklad (např. hodnocení knížky) |
| řazení (ranking) | úkol uspořádat příklady (např. doporučení knížek) |
| detekce anomálií | úkol odhalit příklady, které se výrazně liší od zbytku dat |
| shlukování (clustering) | úloha rozdělit příklady do skupin (shluků, clusters) s podobnými vlastnostmi |
| generativní umělá inteligence (generative AI) | modely generující komplexní výstupy, např. odpovědi nebo obrázky |
| lineární model | model určující výstup na základě váženého součtu atributů |
| rozhodovací strom (decision tree) | model určující výstup na základě posloupnosti podmínek |
| náhodný les (random forest) | model složený z mnoha rozhodovacích stromů |
| neuronová síť | model volně inspirovaný strukturou mozku, složený z mnoha propojených „neuronů“ počítajících jednoduchou funkci, typicky organizovaných do vrstev |
| hluboké učení (deep learning) | učení neuronových sítí s mnoha vrstvami |
| velký jazykový model (Large Language Model, LLM) | rozsáhlá neuronová síť predikující pravděpodobnost dalšího slova (např. GPT) |
| transformátor (transformer) | typ neuronové sítě umožňující efektivní učení na rozsáhlých datech (T v GPT znamená právě transformátor) |
| parametry, váhy | hodnoty modelu, které lze měnit během učení |
| gradientní sestup (gradient descent) | učící algoritmus, který opakovaně mění parametry modelu ve směru největší změny (gradientu) chybové funkce |
| stochastický gradientní sestup (SGD) | efektivní varianta gradientního sestupu využivají prvek náhodnosti |
| trénovací data | data použitá k učení modelu |
| testovací data | data použitá k vyhodnocení modelu |
| generalizace | schopnost predikovat správné výstupy i pro nová data (tedy zobecňovat) |
| memorizace | pouhé zapamatování správných výstupů trénovací data |
| podučení (underfitting) | model má vysokou chybovost, protože je příliš jednoduchý na danou úlohu |
| přeučení (overfitting) | přesné zapamatování trénovacích dat na úkor schopnosti generalizovat |
| regularizace | metody zabraňující přeučení, např. penalizace komplexity modelu |
| zkreslení, předpojatost, (bias) | systematická chyba, která vede k neférovým důsledkům |
| výběrové zkreslení (selection bias) | typ zkreslení, kdy data nereprezentují adekvátně všechny typy případů |
| základní model (baseline) | jednoduché řešení úlohy použité pro srovnání se složitějšími metodami |
| metrika | hodnota vyjadřující kvalitu modelu |
| střední kvadratická chyba (mean squared error) | metrika pro regresní úlohy, průměrná druhá mocnina odchylky mezi predikovanou a skutečnou hodnotou |
| správnost (accuracy) | metrika pro klasifikační úlohy, podíl správných odpovědí |
| přesnost (precision) | metrika pro klasifikační úlohy, kolik ze všech označených příkladů je pozitivních |
| pokrytí (recall) | metrika pro klasifikační úlohy, kolik ze všech pozitivních příkladů model detekoval |
| matice záměn (confusion matrix) | tabulka zobrazující, kolik kterých kategorií bylo jak klasifikováno |
| tenzorové procesy, TPU (Tensor Processing Unit) | procesory specializované na strojové učení |
Metody strojového učení
Obecný postup strojového učení zahrnuje volbu výpočetního modelu pro řešení dané úlohy, jehož parametry poté učíme ve fázi trénování modelu. Témata v této kapitole podrobněji představují několik modelů, které se ve strojovém učení často využívají:
- lineární modely – určují výstup pomocí lineární funkce
- rozhodovací stromy – určují výstup pomocí řady podmínek
- neuronové sítě – kombinují velké množství jednoduchých funkcí (tzv. neuronů)
- pravděpodobnostní modely – pracují s nejistotou (např. Naivní Bayesův klasifikátor)
Lineární regrese
Regrese (v kontextu strojového učení) je úloha odhadnout číselnou hodnotu nějaké veličiny v závislosti na jednom či více atributech (např. odhadování ceny bytu na základě jeho rozlohy). Lineární regrese je řešení regresní úlohy pomocí lineárního modelu, tedy modelu, který je lineární funkcí (tj. váženým součtem) optimalizovaných parametrů.
Nejjednodušším příkladem lineární regrese je hledání přímky \hat{y} = ax + b, která co nejlépe popisuje vztah mezi souřadnicemi x a y zadaných bodů D = \{(x_1, y_1), (x_2, y_2), \ldots, (x_n, y_n)\}. V případě výše je x rozloha, y skutečná cena bytu a \hat{y} odhad ceny podle modelu. Model má dva parametry (a, b), které je potřeba určit (učení modelu, optimalizace).
Kvadratická chyba
Abychom mohli vybrat „nejlepší“ přímku, musíme stanovit chybovou funkci popisující, jak dobře daná přímka odpovídá zadaným bodům. Nejčastěji se používá kvadratická chyba, definovaná jako součet druhých mocnin odchylek jednotlivých odhadů oproti skutečnosti. Tento přístup se označuje jako metoda nejmenších čtverců, protože minimalizujeme součet druhých mocnin, tedy čtverců. Chyba závisí na parametrech a, b a množině bodů D:
E(a, b, D) = \sum_{(x,y) \in D} (\hat{y} - y)^2 = \sum_{(x,y) \in D} (ax + b - y)^2
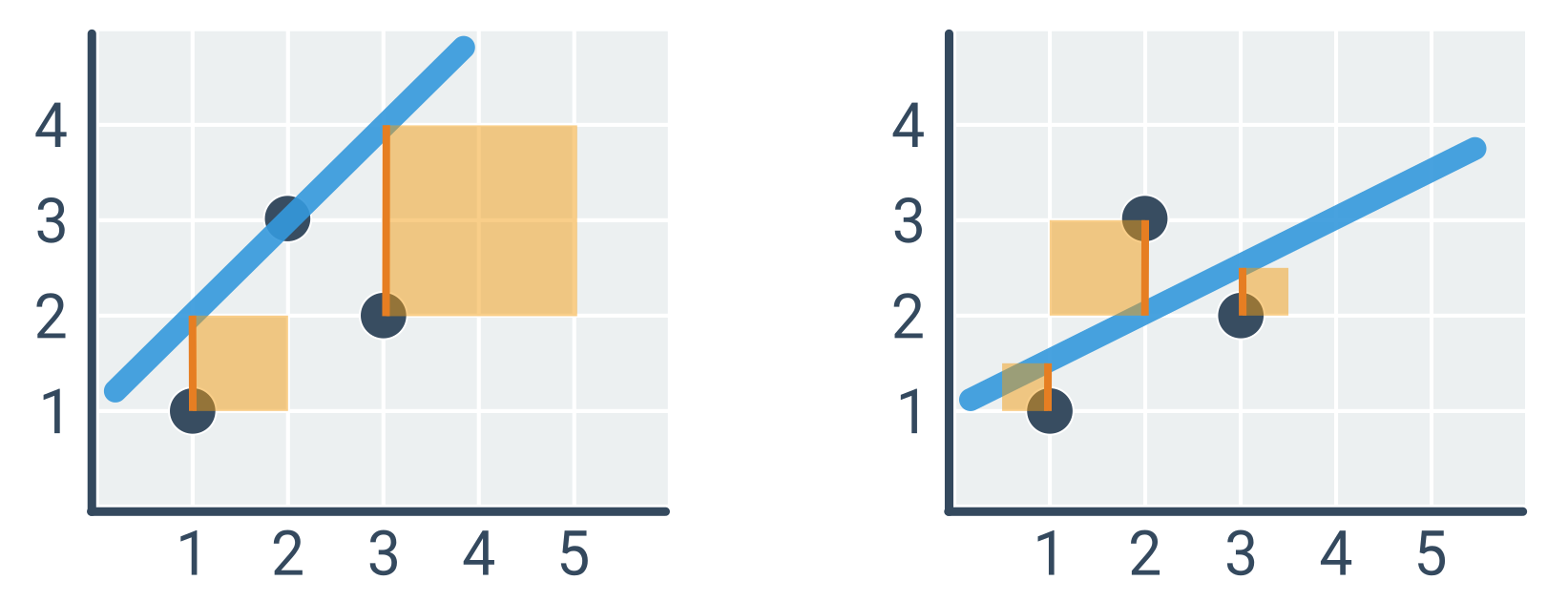
Přímka vlevo (\hat{y} = × + 1) má kvadratickou chybu 1^2 + 2^2 = 5, zatímco přímka vpravo (\hat{y} = 0{,}5x + 1) pouze 0{,}5^2 + 1^2 + 0{,}5^2 = 1{,}5.
Kvadratická chyba je vzhledem k mocnění odchylek citlivá na odlehlé body (outliery), tedy body, které leží daleko od ostatních. Někdy se proto odlehlé body odstraňují, v každém případě je o nich dobré vědět.
Optimalizace parametrů
Úlohou je tedy najít takové hodnoty parametrů a, b, které minimalizují kvadratickou chybu. K optimalizaci existuje řada obecných přístupů, např. systematické zkoušení různých kombinací hodnot parametrů (hrubá síla), nebo postupné vylepšování jedné kombinace parametrů drobnými úpravami (gradientní sestup). V případě lineární regrese lze však optimální parametry určit analyticky, tj. přímým výpočtem pomocí následujících vzorců:
a = \frac{\sum (x - \bar{x})(y - \bar{y})}{\sum (x - \bar{x})^2}
b = \bar{y} - a\bar{x}
Sumy \sum značí součet přes všechny body (x, y) \in D. \bar{x}, \bar{y} jsou průměrné hodnoty x a y. Směrnice a je tedy tím vyšší, čím je mezi x a y silnější vztah a čím jsou odchylky y větší relativně vůči odchylkám x. Rovnici pro b dostáváme z intuitivního vztahu mezi průměrnými hodnotami: \bar{y} = a\bar{x} + b. (Vzorce lze odvodit skrze derivaci kvadratické chybové funkce, která musí být v minimu rovna 0.)
Příklad výpočtu optimální přímky
Hledáme parametry a, b pro body na obrázku výše, tedy D = \{(1, 1), (2, 3), (3, 2)\}.
- \bar{x} = 2, \bar{y} = 2
- (x - \bar{x}) = [-1, 0, 1]
- (y - \bar{y}) = [-1, 1, 0]
- \sum (x - \bar{x})(y - \bar{y}) = (-1) \cdot (-1) + 0 \cdot 1 + 1 \cdot 0 = 1
- \sum (x - \bar{x})^2 = (-1)^2 + 0^2 + 1^2 = 2
- a = 1 / 2 = 0{,}5
- b = \bar{y} - a\bar{x} = 2 - 0{,}5 \cdot 2 = 1
Optimální přímka je tedy \hat{y} = 0{,}5x + 1 (což odpovídá obrázku vpravo).
Obecná lineární regrese
Atributů, na základě kterých děláme odhady, je typicky více. Lineární model má pak parametr pro každý atribut. Například chceme odhadovat rychlost zvířete na základě jeho váhy a délky končetin:
\hat{y} = w_0 + w_1 x_1 + w_2 x_2
\hat{y} je odhad rychlosti, x_1 je váha, x_2 je délka končetin a w_i jsou parametry modelu, které se učíme (jako a, b v případě modelu s jedním atributem). Pro výpočet optimálních parametrů existuje vzorec, který je zobecněním výše uvedených vzorců pro přímku.
Lineární model může mít členy i pro nelineární transformace atributů. Například bychom pro odhad rychlosti zvířete mohli využít druhou mocninu jeho váhy: \hat{y} = w_0 + w_1 x_1 + w_2 x_2 + w_3 x_1^2. Důležité je, že funkce je lineární vzhledem k parametrům w_i, protože ostatní hodnoty jsou konkrétní čísla odvozená z atributů příkladu.
Lineární modely jsou dobře interpretovatelné. Čím vyšší je absolutní hodnota parametru, tím vyšší má přidružený atribut vliv na odhadovanou hodnotu. Pokud je parametr kladný, pak s rostoucí hodnotou atributu roste odhadovaná hodnota, zatímco pokud je parametr záporný, pak s rostoucí hodnotou atributu odhadovaná hodnota klesá.
Rozhodovací stromy
Rozhodovací strom (angl. decision tree) zachycuje proces rozhodování na základě postupně kladených otázek (podmínek). Rozhodování podle rozhodovacích stromů si můžete procvičit ve cvičení Deaktivace bomby: rozhodovací stromy. Rozhodovací stromy se využívají ve strojovém učení jako jeden z modelů, podobně jako třeba lineární modely nebo neuronové sítě.
Určení predikce podle rozhodovacího stromu
Proces rozhodování lze zachytit diagramem ve tvaru stromu (typ grafu), jehož vnitřní uzly obsahují podmínky a listy (koncové uzly, které se již nevětví) obsahují predikce. První podmínka je v kořenovém uzlu a dále postupujeme po hranách (šipkách) do levého nebo pravého podstromu podle toho, zda podmínka pro daný příklad platí, nebo neplatí. Cestu z kořene do listu lze interpretovat jako složenou podmínku spojenou s jedním klasifikačním pravidlem. Nejpravější větev následujícího stromu zachycuje pravidlo: „Pokud má příšerka alespoň 4 ruce a alespoň 5 očí, tak je zlá.“.
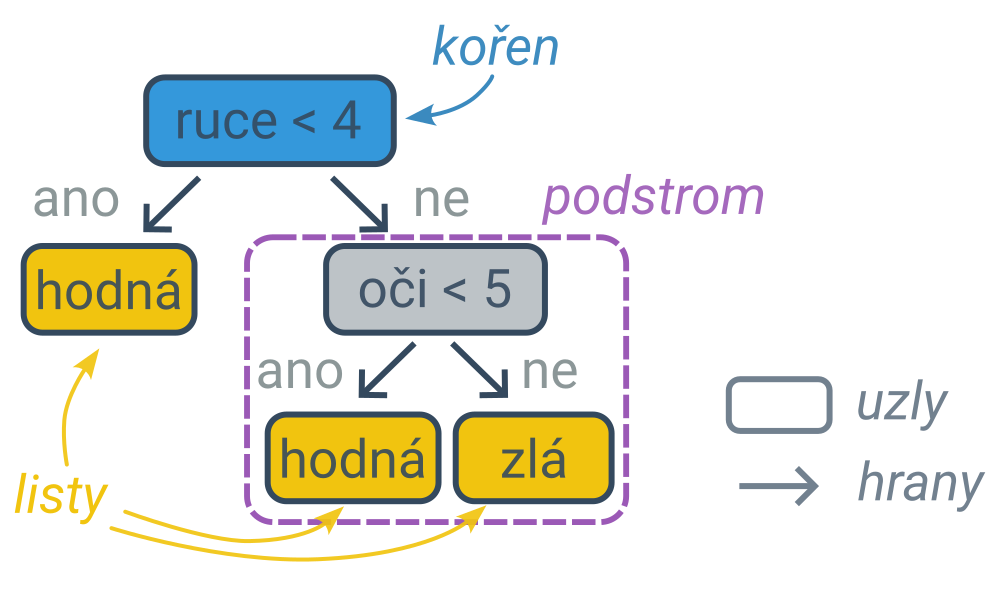
Rozhodovací stromy lze využít na řešení klasifikačních i regresních úloh. Klasifikační rozhodovací strom má v listech predikované kategorie, regresní klasifikační strom predikované číselné hodnoty.
Učení rozhodovacích stromů
V případě klasifikačních úloh hledáme takový rozhodovací strom, který maximalizuje správnost (počet správně klasifikovaných případů, angl. accuracy) na zadané trénovací množině příkladů. Možných stromů je příliš mnoho na to, abychom mohli vyzkoušet všechny, proto strom tvoříme postupným přidáváním uzlů s podmínkami. (Tento přístup, kdy děláme lokálně optimální rozhodnutí, která však negarantují celkově optimální výsledek, se označuje jako hladový algoritmus.)
Začínáme s celým datasetem příkladů a hledáme podmínku, která rozdělí příklady na dvě co nejhomogenější skupiny. (Ideální podmínka by platila pro všechny příklady jedné kategorie a neplatila pro všechny příklady druhé kategorie – pak bychom totiž dosáhli nejvyšší možné správnosti predikcí.) Míru nehomogenity lze kvantifikovat například pomocí entropie nebo Gini indexu, což jsou podobné funkce, které jsou nulové pro zcela homogenní rozdělení a nejvyšší hodnotu mají pro rovnoměrné rozdělení (půlka příkladů z první kategorie, půlka příkladů z druhé kategorie).
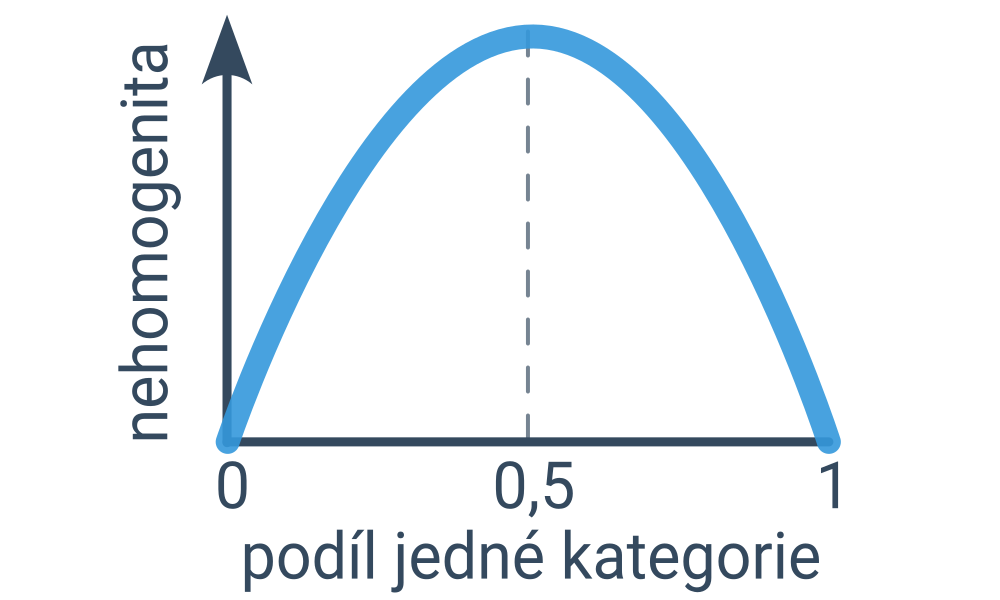
Vybraná nejlepší podmínka se stává kořenem stromu. Stejný proces pak opakujeme pro každý podstrom, dokud dochází k zvyšování homogenity, dokud máme v uzlu dostatek příkladů a/nebo dokud strom není příliš hluboký. Predikce potom odpovídá nejčastější kategorii příkladů, které prošly do tohoto listu. (V případě regresních rozhodovacích stromů by to byla průměrná hodnota příkladů.)
Výhody a nevýhody rozhodovacích stromů
Rozhodovací stromy jsou jednoduché a velmi dobře interpretovatelné. Stromy lze přirozeně vizualizovat a pro jednotlivé predikce lze generovat jasná vysvětlení – složené podmínky dané cestou z kořene do listu. Tyto podmínky jsou navíc nad původními atributy, neboť rozhodovací stromy nevyžadují normalizaci atributů (oproti např. lineárním modelům). Rozhodovací stromy umožňují zachytit nelineární interakce mezi atributy, naopak však nedokáží efektivně zachytit lineární vztahy (jen přibližně pomocí velkého množství podmínek).
Rozhodovací stromy jsou náchylné k přeučení, čemuž lze předejít omezením hloubky a prořezáváním větví, které příliš nepřispívají k celkové správnosti predikcí. I při těchto opatřeních jsou však stromy nestabilní – malá změna dat může výrazně ovlivnit výsledný strom. Nestabilní jsou i jednotlivé predikce – malá změna jednoho atributu může způsobit skokovou změnu predikované hodnoty.
Rozšíření rozhodovacích stromů
Složitější modely kombinují více rozhodovacích stromů do jednoho modelu, aby zvýšili kvalitu predikcí. Náhodný les (angl. random forest) je agregace velkého množství rozhodovacích stromů naučených na náhodných podmnožinách trénovacích dat, jejichž predikce se průměrují. To zvyšuje stabilitu predikcí a snižuje náchylnost k přeučení. Nevýhodou je výrazně horší interpretovatelnost.
Neuronové sítě
Neuronová síť je výpočetní model volně inspirovaný fungováním mozku. Skládá se z mnoha propojených neuronů, které počítají jednoduché funkce. Protože je ale neuronů hodně, je výsledná funkce určená neuronovou sítí složitá.
Neurony
Každý neuron přijímá signál z několika jiných neuronů, signály zpracuje a výsledek posílá dál do napojených neuronů. Signálem putujícím mezi dvěma neurony je jedno reálné číslo. Jednotlivé neurony počítají vážený součet vstupů upravený nelineární aktivační funkcí (např. \max(\cdot, 0)), tj. y = g(\sum_i w_i x_i), kde g je aktivační funkce, w jsou váhy a x jsou vstupní hodnoty.
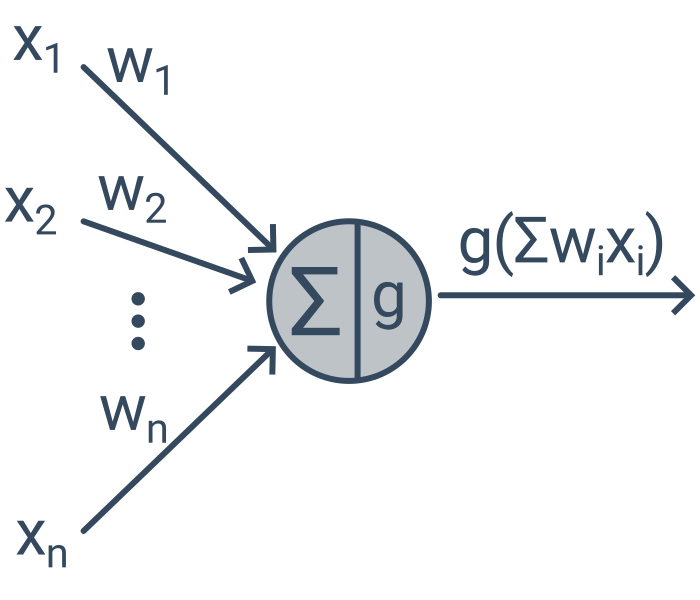
Perceptron je nejjednodušší neuronová síť – obsahuje jediný neuron. Taková síť je velmi podobná lineárnímu modelu. Většinou však neuronové sítě obsahují tisíce či miliony neuronů.
Struktura neuronové sítě
Neurony jsou typicky uspořádané do několika vrstev (vstupní, několik skrytých a nakonec výstupní). Příklad, o kterém chceme něco rozhodnout (např. obrázek, věta, stav hry), je zakódován pomocí hodnot neuronů ve vstupní vrstvě. Skryté vrstvy pak z příkladu extrahují postupně komplexnější vzory. (První skrytá vrstva například detekuje hrany a barevné pásy, druhá vrstva rohy a oblouky, další vrstva základní tvary, další vrstvy postup složitější tvary.) Výstupní vrstva pak obsahuje výslednou predikci (např. určení objektu na obrázku, pokračování rozepsané věty, vhodný tah). Pro neuronové sítě s mnoha vrstvami se používá označení hluboké.
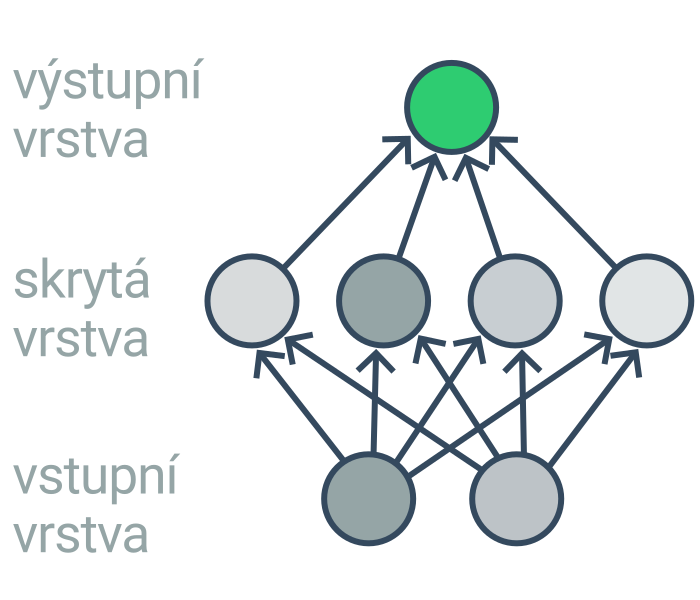
Základní architekturou je vícevrstvý perceptron, ve kterém jsou neurony v každé vrstvě propojeny se všemi neurony ve vrstvě následující. Alternativou jsou například konvoluční neuronové sítě, v nichž některé vrstvy provádí konvoluci – operaci, při které posouváme malý filtr přes celá data (např. každý pixel nahradíme váženým součtem pixelů v okolí). Konvoluční sítě se hodí na zpracování dat s prostorovou strukturou (např. obrázky).
Sítě, ve kterých informace putuje jedním směrem (tj. síť neobsahuje cykly) se označují jako dopředné. Opakem dopředných sítí jsou rekurentní neuronové sítě, které obsahují neurony, jejichž výstup je současně jejich vstupem (neuron má tedy v podstatě paměť). Rekurentní sítě se hodí pro zpracování sekvenčních dat (např. text). Výpočet a učení rekurentních neuronových sítí je však složitější než sítí dopředných.
Proto se v poslední době i pro sekvenční data častěji využívají trasnformátory, dopředné sítě, které transformují celé sekvence naráz a používají mechanismus pozornosti určující, na kterou část dosavadní sekvence se zaměřit. Transformátory se používají pro zpracování textu, zvuku i obrazu. (Např. GPT znamená „generativní předtrénovaný transformátor“.)
Učení neuronových sítí
Neuronová síť je v podstatě komplikovaná funkce s mnoha parametry (váhy mezi neurony). Učení sítě je optimalizační úloha hledání takových vah, které minimalizují chybu predikcí sítě na trénovacích datech. Příkladem chybové funkce je kvadratická chyba – součet druhých mocnin odchylek mezi predikovanou a skutečnou hodnotou (přes všechny příklady v trénovacích datech).
K učení se využívá algoritmus gradientního sestupu: začneme s náhodnými hodnotami parametrů a ty pak opakovaně upravujeme tak, abychom zmenšili chybu. Gradient je směr, ve kterém funkce nejrychleji roste, postupujeme tedy proti směru gradientu. Gradient lze spočítat algoritmem zpětného šíření chyby (angl. backpropagation): pro každý příklad v trénovací sadě provedeme dopředný výpočet sítě, porovnáme predikci se skutečností a upravíme všechny váhy (postupně od poslední k první vrstvě) tak, aby se chyba snížila.
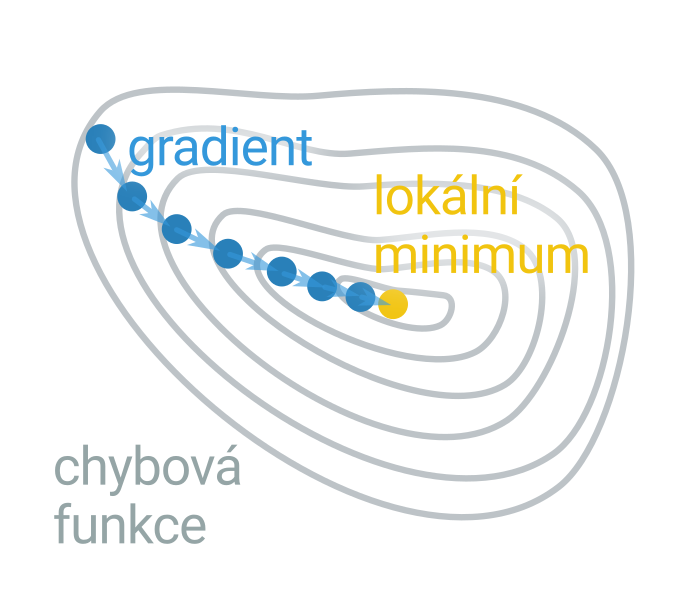
Učení hlubokých neuronových sítí je obtížné kvůli problému mizejícího gradientu – gradient exponenciálně klesá se vzdáleností neuronu od výstupu sítě. Výzkum v oblasti neuronových sítí přináší stále nové techniky, jak tento problém zmírnit, jako nejdůležitější se však ukazuje výpočetní výkon. Pro urychlení výpočtů se využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit), i tak však učení rozsáhlých modelů může trvat mnoho dní.
Neuronové sítě mají mnoho parametrů, hrozí proto riziko přeučení, kdy si síť pouze zapamatuje přesné odpovědi pro trénovací data, ale není schopna generalizovat na nové příklady. Pro učení neuronových sítí je proto potřeba velké množství příkladů a využití regularizačních technik, které riziko učení snižují (např. penalizace příliš vysokých vah).
Kromě vah v neuronové síti můžeme optimalizovat i její strukturu (např. počet vrstev) a parametry učení (např. velikost kroku při gradientním sestupu). Tyto speciální parametry ovlivňující ostatní parametry se označují jako hyperparametry. Jejich hodnota je během učení gradientním sestupem konstantní, můžeme je však optimalizovat mřížkovým prohledáváním, při kterém zkoušíme naučit síť pro různé volby hyperparametrů.
Využití
Neuronové sítě mají využití zejména v oblastech, kde je k dispozici velké množství dat k učení, je obtížné přesně popsat užitečné rysy příkladů manuálně a nepotřebujeme vysvětlení výsledných predikcí. Používají se pro zpracování přirozeného jazyka (odpovídání na otázky, strojový překlad, rozpoznávání řeči), počítačové vidění (klasifikace obrázků, generování obrázků, analýza medicínských měření), řízení a rozhodování (hraní šachů, řízení autonomních vozidel) a predikci struktury či budoucího vývoje (predikce 3D struktury proteinů, odhadování vývoje cen akcií).
Pravděpodobnost ve strojovém učení
Pravděpodobnost umožňuje pracovat s nejistotou, která je ve strojovém učení nevyhnutelná, neboť model musí odhadovat odpovědi i pro nové příklady, které nikdy předtím neviděl.
Základy pravděpodobnosti
Pravděpodobnost P(A) je číslo mezi 0 a 1 vyjadřující míru jistoty či očekávání, že se jev A stal nebo stane. Pokud ze 200 e-mailů 10 obsahuje slovo „zázračný“, pak je pravděpodobnost výskytu slova „zázračný“ P(„zázračný“) = 0,05 = 5 %. Pravděpodobnost opačného jevu \neg A je doplněk do jedničky, tj. P(\neg A) = 1-P(A). Pravdědodobnost, že e-mail neobsahuje slovo „zázračný“, je 0,95.
Podmíněná pravděpodobnost P(A \mid B) je pravděpodobnost jevu A za předpokladu, že nastal jev B. Podmíněnou pravděpodobnost spočítáme jako P(A \mid B) = P(A \cap B) / P(B), kde P(A \cap B) je pravděpodobnost současného výskytu obou jevů. Pokud mezi 200 e-maily bylo 20 spamů a z nich 8 obsahovalo slovo „výhra“, tak podmíněná pravděpodobnost, že e-mail obsahuje slovo „zázračný“, pokud je spam, je P(„zázračný“ | spam) = P(„zázračný“ ∩ spam) / P(spam) = 8 / 20 = 0,04 = 40 %.
Pokud jev B nijak neovlivňuje pravděpodobnost jevu A, tj. P(A \mid B) = P(A), pak označujeme jevy A, B jako nezávislé. Například hody mincí jsou nezávislé. Naopak výskyt slova „zázvračný“ není nezávislý na tom, zda jde o spam. Pravděpodobnost současného výskytu nezávislých jevů je rovna součinu jednotlivých pravděpodobností, tedy P(A \cap B) = P(A) \cdot P(B). (Obecně pro libovolné jevy platí P(A \cap B) = P(A) \cdot P(B \mid A) = P(B) \cdot P(A \mid B).)
Výpočty s pravděpodobností si můžete procvičit na Umíme matiku.
Bayesova věta
Často umíme snadno určit P(B \mid A), kde A způsobuje nebo ovlivňuje B, ale zajímá nás opačná podmíněná pravděpodobnost P(A \mid B). Z posbíraných dat umíme snadno vypočítat pravděpodobnost, že e-mail obsahuje slovo „zázračný“, pokud jde o spam, ale pro klasifikaci e-mailů potřebujeme znát opačnou podmíněnou pravděpodobnost – pravděpodobnost, že jde o spam, když text obsahuje slovo „zázračný“. V takových případech lze podmíněnou pravděpodobnost „otočit“ podle Bayesovy věty:
P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}
Odvození Bayesovy věty
Pravděpodobnost, že nastane A i B, můžeme vyjádřit pomocí dvou různých podmíněných pravděpodobností (z definice podmíněné pravděpodobnosti):
P(A \cap B) = P(A \mid B) \cdot P(B)
P(A \cap B) = P(B \mid A) \cdot P(A)
Porovnáním pravých stran dostaneme:
P(A \mid B) \cdot P(B) = P(B \mid A) \cdot P(A)
Podělením obou stran P(B) již získáme Bayesovu větu:
P(A \mid B) = P(B \mid A) \cdot P(A) \mathbin{/} P(B)
Vzorec lze také vnímat jako update původní (nepodmíněné) pravděpodobnosti P(A) (prior) s přihlédnutím k nové informaci, že nastal jev B. Zpřesněná (podmíněná) pravděpodobnost P(A \mid B) se pak označuje jako posterior.
Příklad použití Bayesovy věty
Chceme určit pravděpodobnost, že má pacient rakovinu, pokud má pozitivní test. Prevalence rakoviny v testované populaci je 1 %. Pokud má pacient rakovinu, pak je test pozitivní v 90 %, pokud pacient rakovinu nemá, pak je test pozitivní ve 20 %.
Označme si T = pozitivní test, R = rakovina. Ze zadání víme: P(R) = 0{,}01, P(T \mid R) = 0{,}9, P(T \mid \neg R) = 0{,}2.
K použití Bayesovy věty potřebujeme spočítat celkovou pravděpodobnost pozitivního testu:
P(T) = P(R) \cdot P(T \mid R) + P(\neg R) \cdot P(T \mid \neg R)
Podle Bayesovy věty:
P(R \mid T) = P(R) \cdot P(T \mid R) / P(T) = 0{,}01 \cdot 0,9 / (0{,}01 \cdot 0{,}9 + 0{,}99 \cdot 0{,}2) = 0{,}009 / (0{,}009 + 0{,}198) = 0{,}009 / 0{,}207 = 0{,}043 = 4{,}3 \%
Pravděpodobnost rakoviny je tedy v této situaci i při pozitivním testu pouze 4,3 %. To se může zdát málo, ale je to dáno tím, že test je nezřídka pozitivní i pro pacienty bez rakoviny a těch je přitom v populaci výrazně více.
Pravděpodobnostní klasifikátor
Pravděpodobnostní modely lze nejsnáze využít pro řešení klasifikačních úloh (např. rozhodnout, zda je daný e-mail spam). Označme X příklad, který chceme klasifikovat, X_1, X_2, \ldots, X_n jeho jednotlivé atributy (např. přítomnost různých slov v textu e-mailu) a Y možné kategorie (spam / normální e-mail). Chceme predikovat kategorii s větší podmíněnou pravděpodobností P(Y \mid X). Tyto pravděpodobnosti můžeme spočítat s využitím Bayesovy věty:
P(Y \mid X) = P(X \mid Y) \cdot P(Y) \mathbin{/} P(X)
Zatímco určení P(Y) je snadné (spočítáme, jaký podíl e-mailů v trénovacích datech jsou spam), určení P(X \mid Y) vyžaduje exponenciálně mnoho příkladů vzhledem k počtu atributů (potřebovali bychom e-maily se všemi možnými kombinacemi uvažovaných slov). Možným řešením je pravděpodobnostní rozdělení odhadovat pouze přibližně pomocí nějakého modelu, který nemá exponenciální počet parametrů (např. neuronová síť).
Naivní Bayesův klasifikátor
Pro mnohé jednoduché problémy však stačí výrazně jednodušší řešení: předpokládat, že jednotlivé atributy jsou na sobě podmíněně nezávislé (při znalosti kategorie). Pak nám totiž stačí n jednoparametrických podmíněných pravědpodobností:
P(Y \mid X) = P(Y) \cdot P(X_1 \mid Y) \cdot P(X_2 \mid Y) \cdot \ldots \cdot P(X_n \mid Y) \mathbin{/} P(X)
Tento model se označuje jako Naivní Bayesův klasifikátor. Slovo „naivní“ se odkazuje právě na předpoklad podmíněné nezávislosti atributů, který typicky neplatí (např. přítomnost slova „zázračný“ zvyšuje pravděpodobnosti slova „lék“ i pokud víme, že jde o spam). Odhadnuté pravděpodobnosti tak můžou být hodně nepřesné. Pro úspěšnou klasifikaci však není podstatné, zda jsou pravděpodobnosti odhadnuté přesně, ale zda má skutečná kategorie nejvyšší odhadnutou pravděpodobnost, což často platí. Výhodou je nízký počet parametrů (lineární vzhledem k počtu atributů), nízký počet příkladů potřebných k učení a také rychlé učení (přímočarý výpočet hodnot parametrů).
Bayesovské sítě
Naivní Bayesův klasifikátor předpokládá, že jsou všechny atributy podmíněně nezávislé. V některých případech víme, že některé atributy nezávislé jsou a jiné nejsou. Takovou situaci můžeme modelovat pomocí Bayesovských sítí, což je orientovaný graf zachycující vztahy mezi pozorovanými a skrytými proměnnými (pozorované proměnné jsou na obrázcích níže podbarvené šedě):
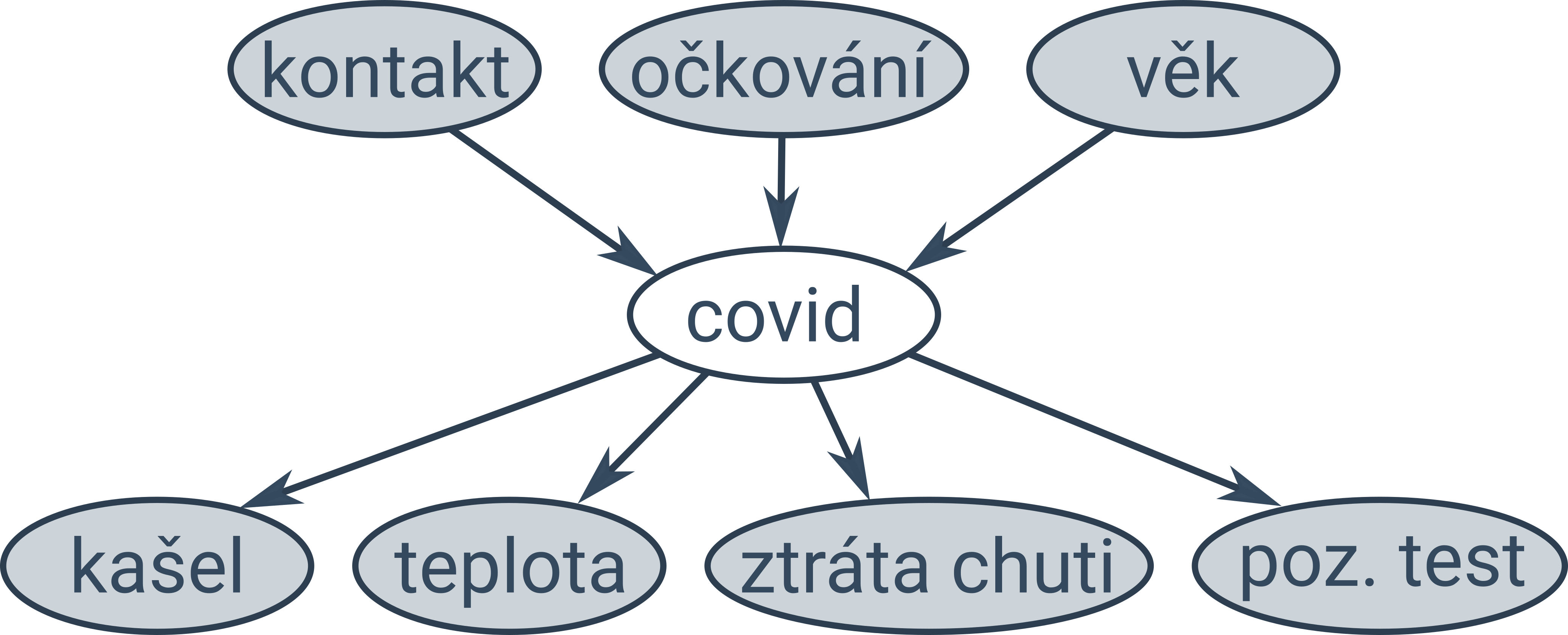
Naivní Bayesův klasifikátor je speciální typ Bayesovské sítě s následující jednoduchou strukturou:
Existují další speciální typy Bayesovských sítí, např. skryté Markovovy modely, znázorňujı́cı́ časovou posloupnost skrytých stavů (poloha robota, vyslovovaný text), v nı́ž každý stav závisı́ pouze na jednom předchozı́m stavu a produkuje pozorovatelné měření (měření ultrazvukového senzoru, zaznamenaný zvuk).