
Základy strojového učení
Základy strojového učení
Strojové učení je podoblast umělé inteligence zabývající se tvorbou programů, které se učí z dat. Strojové učení souvisí s tématem práce s daty, zejména s jejich sběrem a evidencí. V rámci základního přehledu strojového učení najdete na Umíme následující témata:
- princip strojového učení – co to je strojové učení, v čem spočívá rozdíl oproti klasickému programování, na co se strojové učení hodí
- typy úloh, které lze pomocí strojového učení řešit (např. klasifikace, regrese, shlukování)
- postup řešení těchto úloh (např. učení s učitelem a bez učitele, neuronové sítě a jiné modely)
- vyhodnocení naučených modelů (rozlišení mezi generalizací a pouhou memorizací, rozpoznání podučení a přeučení, srovnání kvality různých modelů)
- zkreslení (předpojatost) ve strojovém učení (co to je, jak rozpoznat a co se s tím dá dělat)
- pojmy často používané v textech o strojovém učení
Princip strojového učení
Umělá inteligence často využívá učení z dat, tzv. strojové učení. Vstupem strojového učení je velké množství dat (dataset), výstupem je naučený model pro řešení požadovaného úkolu. Máme-li dostatek dat popisujících vzhled a chování příšerek, můžeme naučit model, který bude pro nové příšerky odhadovat, zda jsou hodné, na základě jejich vzhledu.
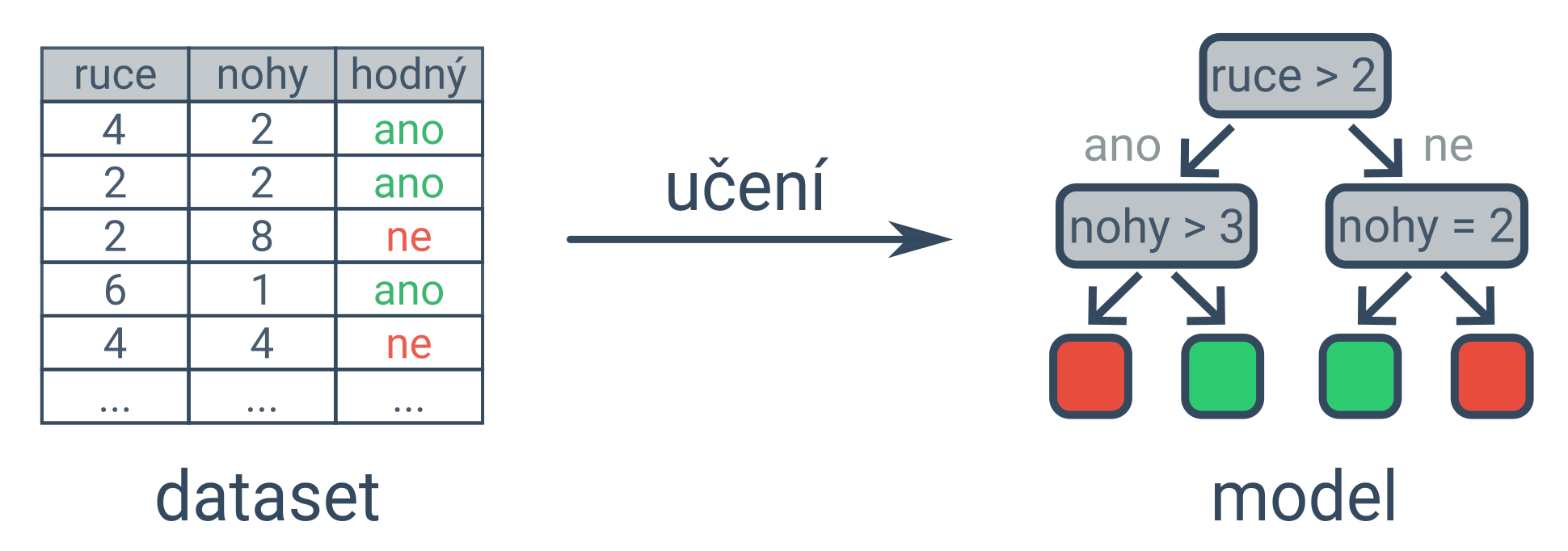
Klíčovou ingrediencí pro strojové učení je velké množství dat. Jednotlivé příklady jsou typicky poměrně jednoduché (např. jedna fotka), ale je jich hodně (někdy i miliony). Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data (memorizace), musí být schopen určovat správný výstup i pro příklady nové (zobecňování, generalizace).
Příkladem modelu je rozhodovací strom (na obrázku výše) nebo neuronová síť (model volně inspirovaný sítí neuronů v mozku). Strojové učení může v závislosti na množství dat trvat vteřiny i celé dny, pro urychlení se proto někdy využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit).
Strojové učení lze vnímat jako alternativu ke klasickému programování, při kterém programátor zapisuje posloupnost přesných instrukcí (např. if-then pravidla nebo heuristika na základě zkušenosti). Strojové učení bude vhodným přístupem zejména tehdy, když není jasné, jak by takový klasický program měl vypadat a přitom lze sehnat rozsáhlé množství příkladů (např. detekce spamu). Strojové učení spíše nebude vhodným přístupem pro kritická rozhodnutí, kde není tolerovatelná žádná chyba a potřebujeme vysokou předvídatelnost a transparentnost chování (např. bankovní převod).
Aplikace strojového učení (příklady)
- detekce spamu
- diagnóza nemoci
- rozpoznání hlasu
- překlad textů
- doporučování filmů
- řízení auta
- generování obrázků podle popisu
Úlohy strojového učení
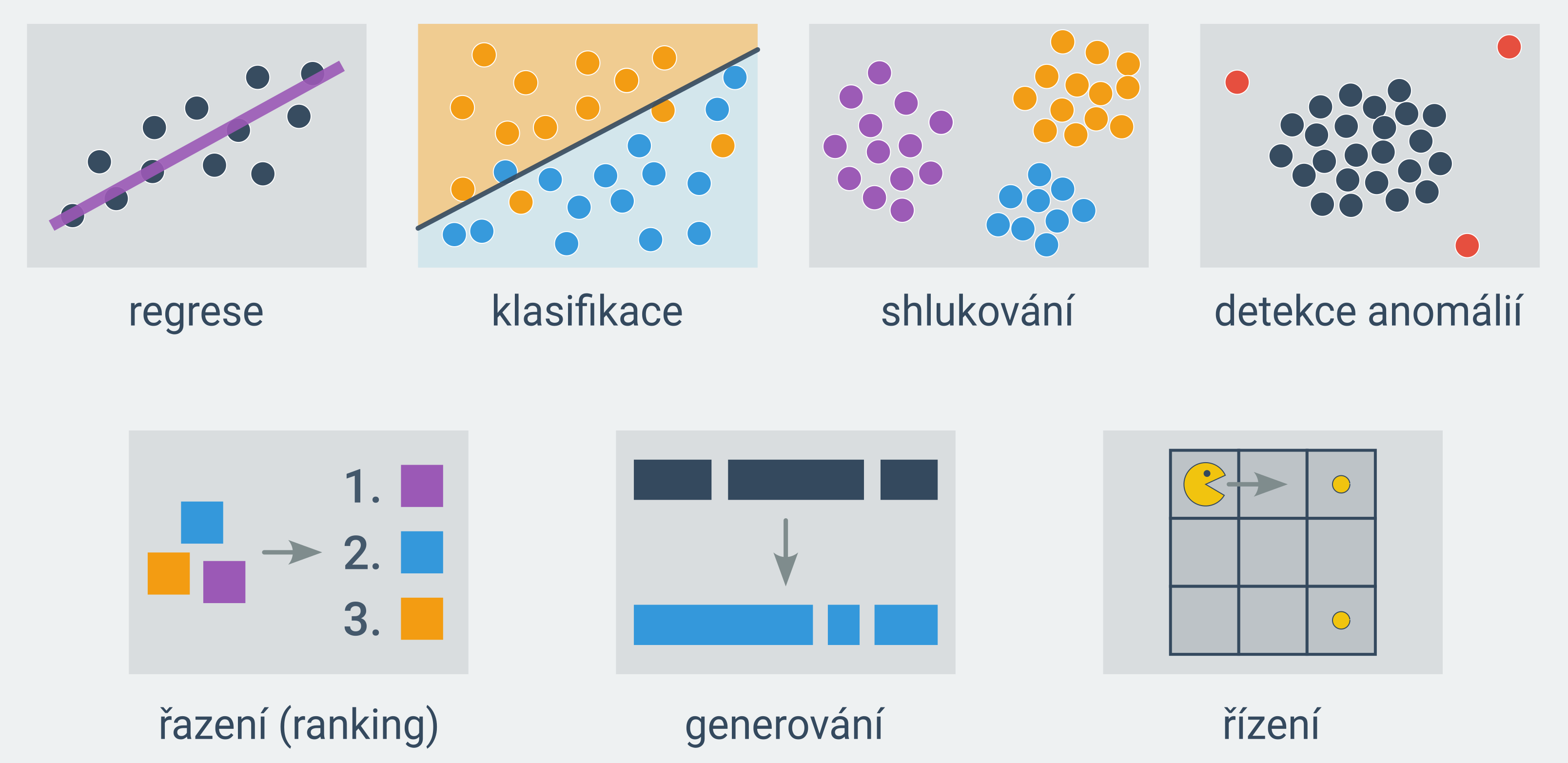
Pomocí strojového učení lze řešit rozličné typy úloh, mezi ty nejčastější patří:
regrese = odhad číselné hodnoty (Jak bude daný uživatel hodnotit daný film? Jaká bude teplota zítra odpoledne?)
klasifikace = určování příslušnosti k jedné z několika předem daných kategorií (Je daný e-mail spam? Která kytka je na fotce?)
shlukování = rozdělení příkladů do skupin s podobnými vlastnostmi (Které zprávy řeší podobné téma? Které chemické látky se chovají podobně?)
hledání anomálií = upozornění na podezřelé příklady, které se výrazně liší od zbytku dat (detekce případů, kdy bankovní účet nevyužívá jeho skutečný majitel)
řazení (ranking) = uspořádání příkladů (seřazení výsledků vyhledávání, seřazení doporučených videí)
generování = vytvoření textu nebo obrázku na základě jiného textu nebo obrázku (odpovídání na otázky, strojový překlad, vygenerování popsaného obrázku)
řízení = hledání strategie pro optimální rozhodování (hraní šachů a podobných her, řízení autonomního auta)
Postup strojového učení
Využití strojového učení zahrnuje následující fáze:
příprava datasetu – může zahrnovat sběr a anotování dat (doplnění požadovaného výstupu)
trénování modelu – určení vhodných hodnot parametrů modelu
testování modelu – na nových datech, které model neviděl během trénování
nasazení modelu – tedy jeho použití pro zadaný úkol
Typy přístupů
Přístupy ke strojovému učení lze rozlišit podle povahy signálu o požadovaném výstupu modelu:
učení s učitelem (angl. supervised learning) – požadovaný výstup je součástí trénovacích dat (např. zda je příšerka hodná, zda je e-mail spam). Doplňování požadovaných výstupů se říká anotování dat. Datům s požadovaným výstupem se pak někdy říká označkovaná data.
učení bez učitele (angl. unsupervised learning) – trénovací data neobsahují požadovaný výstup, úkolem je najít vzory v datech (např. podobné příšerky, podobné zprávy)
posilované učení (někdy též zpětnovazební učení, angl. reinforcement learning) = učení skrze interakci s prostředím zahrnující zpětnou vazbu na provedené akce (např. výhra v šachu, řízení auta bez nehod)
Různé přístupy jsou vhodné na různé typy úloh. Učením s učitelem se typicky řeší regrese, klasifikace, řazení a generování, učením bez učitele shlukování a hledání anomálií, posilovaným učením řízení. Často se však přístupy kombinují.
Modely
Pro řešení úloh strojového učení existuje celá řada modelů. Příkladem jsou lineární modely, rozhodovací stromy a neuronové sítě:
Lineární modely určují výstup na základě váženého součtu atributů. Pokud je 2 × počet rukou + 3 × počet nohou menší než 18, pak je příšerka hodná.
Rozhodovací stromy určují výstup na základě podmínek. Pokud má příšerka (více jak dvě ruce a nejvýše tři nohy) nebo (nejvýše dvě ruce a právě dvě nohy), pak je hodná.
Neuronové sítě se skládají z mnoha propojených neuronů, kde každý neuron počítá relativně jednoduchou funkci (podobně jako lineární model). Protože je ale neuronů hodně, je výsledná funkce určená neuronovou sítí složitá. Neurony jsou typicky uspořádané do několika vrstev. Učení neuronové sítě s mnoha vrstvami se označuje jako hluboké učení (angl. deep learning).
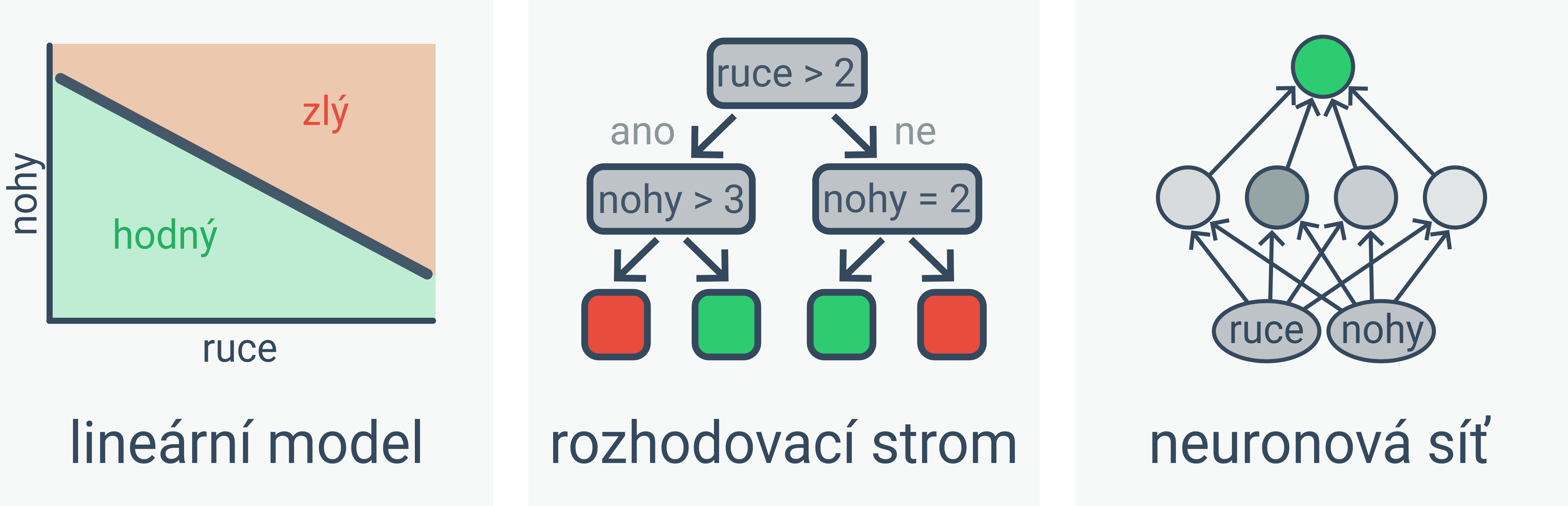
Volba vhodného modelu závisí například na množství dat a požadované interpretovatelnosti výstupů modelu. Neuronové sítě a jiné modely s mnoha parametry se umí naučit velmi složité funkce, ale vyžadují hodně dat a jsou hůře interpretovatelné než lineární modely a rozhodovací stromy.
Učící algoritmy
Učící algoritmus hledá strukturu nebo parametry modelu tak, aby minimalizoval zadanou chybu. Příkladem učícího algoritmu, který se využívá např. pro lineární modely a neuronové sítě, je gradientní sestup (angl. gradient descent). Při gradientním sestupu začneme s náhodnými hodnotami parametrů a ty pak opakovaně upravujeme tak, abychom zmenšili chybu modelu. Jiný učící algoritmus se používá pro budování rozhodovacích stromů: strom postupně zvětšujeme přidáváním rozhodovacích uzlů s podmínkami, které co nejlépe rozdělují příklady.
Příklad učení lineárního klasifikátoru příšerek
Parametry lineárního modelu jsou (a) váha pro počet rukou, (b) váha pro počet nohou a (c) hranice, při které je ještě příšerka klasifikovaná jako hodná: a \cdot \text{[počet rukou]} + b \cdot \text{[počet nohou]} < c
Například pro hodnoty parametrů a = 2, b = 4, c = 20 bude model klasifikovat příšerku jako hodnou tehdy, když 2 \cdot \text{[počet rukou]} + 4 \cdot \text{[počet nohou]} < 20.
Různá nastavení těchto parametrů vedou na různý počet chybně klasifikovaných příšerek. Řekněme, že při hodnotách parametrů a = 2, b = 4, c = 20 model klasifikuje chybně 20 % příšerek. Gradientní sestup by mohl parametry upravit na a = 2, b = 3, c = 18 a snížit tak chybu třeba na 15 %. Gradientní sestup by opakovaně prováděl takovéto drobné úpravy parametrů (spíše ještě drobnější).
Směr změny parametrů, který co nejvíce sníží chybu, závisí na konkrétní chybové funkci a pro mnohé chybové funkce lze tento směr (tzv. gradient) spočítat.
Vyhodnocení strojového učení
Aby byl model užitečný, nestačí aby si zapamatoval trénovací data, musí být schopen určovat správný výstup i pro příklady nové, tedy generalizovat. Kvalitu modelu je proto potřeba vyhodnotit na datech, která model neviděl během učení, jinak bude vyhodnocení neoprávněně optimistické. Situaci, kdy si model zapamatuje přesné odpovědi pro trénovací data, ale není schopen generalizovat, nazýváme přeučení (někdy též přetrénování, angl. overfitting). Situaci, kdy je zvolený model příliš jednoduchý na danou úlohu, takže má vysokou chybu i na trénovacích datech, nazýváme podučení (někdy též podtrénování, angl. underfitting).

Složitější modely jsou typicky náchylnější k přeučení, protože se umí naučit libovolný šum v datech. Pokud jsou dva modely podobně správné na datech, která máme k dispozici, tak pro nová data bude proto pravděpodobněji lépe generalizovat ten jednodušší z nich. Jde o případ obecného principu zvaného Occamova břitva, který říká, že existuje-li více různých vysvětlení, je lépe upřednostňovat to jednodušší z nich.
Kvalitu modelů lze kvantifikovat pomocí různých metrik. Pro vyhodnocení regresních modelů se často používá střední kvadratická chyba (angl. mean squared error), což je průměrná druhá mocnina odchylky mezi predikovanou a skutečnou hodnotou. Pro vyhodnocení klasifikačních modelů se používá například správnost (angl. accuracy, podíl správných odpovědí), přesnost (angl. precision, kolik ze všech označených příkladů je pozitivních) a pokrytí (angl. recall, kolik ze všech pozitivních příkladů model detekoval).
Užitečnou vizualizací je matice záměn (angl. confusion matrix), která zobrazuje, kolik kterých kategorií bylo jak klasifikováno. Následující matice kompaktně zachycuje chování modelu pro predikci nemoci (P – pozitivní, N – negativní), kdy model v 9 případech správně predikoval pozitivní výsledek, v 87 správně predikoval negativní výsledek, v 1 případě chybně predikoval pozitivní výsledek a ve 3 případech chybně predikoval negativní výsledek.

Vždy je vhodné problém nejprve zkusit řešit pomocí jednoduchého základního modelu (angl. baseline), což může být například průměrná hodnota (pro regresi) nebo nejčastější kategorie (pro klasifikaci). Srovnání metrik složitějšího modelu se základním modelem umožňuje hodnoty metrik lépe interpretovat.
Zkreslení strojového učení
Zkreslení (někdy též předpojatost, podjatost, zaujatost, angl. bias) znamená systematickou chybu, která vede k neférovým důsledkům pro různé skupiny. Nemusí jít o skupiny lidí, pojem zkreslení se používá i pro situaci, kdy model např. výrazně častěji predikuje jednu kategorii (např. hrušky), přestože se jiné kategorie (např. jablka) vyskytují podobně často.
Zkreslení modelu může podporovat předsudky (model predikující studijní výsledky v určitém oboru využívající informaci o pohlaví) a vést k diskriminaci (pokud by byl tento model použit pro rozhodování o přijetí na univerzitu).
Zkreslení modelu je většinou způsobeno zkreslenými daty, model se totiž naučí pouze to, co vidí v datech. K výběrovému zkreslení dochází, pokud data nereprezentují adekvátně všechny typy případů. Pokud bychom trénovali rozpoznávání bot pouze na pánských botech, model nebude rozpoznávat dámské boty. Ke zkreslení odpovědí může dojít např. kvůli předsudkům anotujících osob, nebo kvůli neochotě respondentů sdělit pravdu. V dotazníkových šetřeních lidé často upravují svoje odpovědi o sobě podle společenských očekávání.
Zkreslení může být náročné odhalit, protože na rozdíl od přeučení se většinou neprojeví nižší úspěšností na testovacích datech. Při běžném postupu totiž data pro testování a učení pocházejí z jednoho zdroje, takže obsahují tatáž zkreslení.
Abychom snížili riziko zkreslení, je vhodné důsledně kontrolovat kvalitu dat. Měli bychom například ověřit, že posbíraná data obsahují všechny typy případů a že jsou jednotlivé kategorie zastoupeny podobným množstvím příkladů, podobné kvality a v podobných kontextech. Při anotování dat je vhodné, aby ho prováděli lidé z různých skupin (např. muži i ženy). Je také užitečné vyhodnocovat chování modelu pro různé podskupiny dat (např. pro muže a ženy, různé věkové skupiny, menšiny) a průběžně monitorovat chování modelu i po nasazení.
Strojové učení: pojmy
Zde uvádíme přehled pojmů, se kterými se můžete často potkat v textech o strojovém učení. Mnoho z nich zatím nemá ustálené české překlady, proto se i v českých textech často používají anglické výrazy (níže uvedené kurzivou v závorce). Podrobnější vysvětlení jednotlivých pojmů najdete v dílčích tématech strojového učení.
| pojem | popis |
|---|---|
| strojové učení | učení programů na základě dat |
| model | mapování vstupů na výstupy (řešení úlohy strojového učení) |
| datová sada (dataset) | data pro trénování modelu |
| příklad (example) | jeden kompletní vstup pro model (řádek datasetu) |
| atribut (feature) | informace o příkladech použitá modelem (sloupec datasetu) |
| štítek (label) | správný výstup pro daný příklad |
| anotování dat | přiřazování správných výstupů (štítků) |
| označkovaná data | data s požadovaným výstupem (štítkem) |
| predikce | předpověď, odhad (výstup modelu) |
| inference | vytvoření odhadů natrénovaným modelem |
| učení s učitelem (supervised learning) | přístup ke strojovému učení využívající označkovaná data |
| učení bez učitele (unsupervised learning) | přístup ke strojovému učení využívající neoznačkovaná data |
| učení s částečným dohledem (semi-supervised learning) | přístup ke strojovému učení využívající označkovaná i neoznačkovaná data |
| posilované učení, zpětnovazební učení (reinforcement learning) | učení skrze interakci s prostředím zahrnující zpětnou vazbu na provedené akce |
| klasifikace | úloha určit příslušnost příkladu k jedné z několika předem daných kategorií (např. žánr knížky) |
| regrese | úloha určit číselnou hodnotu pro daný příklad (např. hodnocení knížky) |
| řazení (ranking) | úkol uspořádat příklady (např. doporučení knížek) |
| detekce anomálií | úkol odhalit příklady, které se výrazně liší od zbytku dat |
| shlukování (clustering) | úloha rozdělit příklady do skupin (shluků, clusters) s podobnými vlastnostmi |
| generativní umělá inteligence (generative AI) | modely generující komplexní výstupy, např. odpovědi nebo obrázky |
| lineární model | model určující výstup na základě váženého součtu atributů |
| rozhodovací strom (decision tree) | model určující výstup na základě posloupnosti podmínek |
| náhodný les (random forest) | model složený z mnoha rozhodovacích stromů |
| neuronová síť | model volně inspirovaný strukturou mozku, složený z mnoha propojených „neuronů“ počítajících jednoduchou funkci, typicky organizovaných do vrstev |
| hluboké učení (deep learning) | učení neuronových sítí s mnoha vrstvami |
| velký jazykový model (Large Language Model, LLM) | rozsáhlá neuronová síť predikující pravděpodobnost dalšího slova (např. GPT) |
| transformátor (transformer) | typ neuronové sítě umožňující efektivní učení na rozsáhlých datech (T v GPT znamená právě transformátor) |
| parametry, váhy | hodnoty modelu, které lze měnit během učení |
| gradientní sestup (gradient descent) | učící algoritmus, který opakovaně mění parametry modelu ve směru největší změny (gradientu) chybové funkce |
| stochastický gradientní sestup (SGD) | efektivní varianta gradientního sestupu využivají prvek náhodnosti |
| trénovací data | data použitá k učení modelu |
| testovací data | data použitá k vyhodnocení modelu |
| generalizace | schopnost predikovat správné výstupy i pro nová data (tedy zobecňovat) |
| memorizace | pouhé zapamatování správných výstupů trénovací data |
| podučení (underfitting) | model má vysokou chybovost, protože je příliš jednoduchý na danou úlohu |
| přeučení (overfitting) | přesné zapamatování trénovacích dat na úkor schopnosti generalizovat |
| regularizace | metody zabraňující přeučení, např. penalizace komplexity modelu |
| zkreslení, předpojatost, (bias) | systematická chyba, která vede k neférovým důsledkům |
| výběrové zkreslení (selection bias) | typ zkreslení, kdy data nereprezentují adekvátně všechny typy případů |
| základní model (baseline) | jednoduché řešení úlohy použité pro srovnání se složitějšími metodami |
| metrika | hodnota vyjadřující kvalitu modelu |
| střední kvadratická chyba (mean squared error) | metrika pro regresní úlohy, průměrná druhá mocnina odchylky mezi predikovanou a skutečnou hodnotou |
| správnost (accuracy) | metrika pro klasifikační úlohy, podíl správných odpovědí |
| přesnost (precision) | metrika pro klasifikační úlohy, kolik ze všech označených příkladů je pozitivních |
| pokrytí (recall) | metrika pro klasifikační úlohy, kolik ze všech pozitivních příkladů model detekoval |
| matice záměn (confusion matrix) | tabulka zobrazující, kolik kterých kategorií bylo jak klasifikováno |
| tenzorové procesy, TPU (Tensor Processing Unit) | procesory specializované na strojové učení |
