
Metody umělé inteligence
Metody umělé inteligence
Mnoho algoritmických problémů lze formulovat jako jeden z několika typů úloh umělé inteligence, mezi které patří plánování (hledání nejkratší cesty), splňování podmínek (např. sudoku), optimalizace (hledání minima zadané funkce), predikce (odhad hodnoty či kategorie, např. detekce spamu) a generování (např. odpovídání na otázky). Jakmile se nám podaří problém formulovat jako jeden z těchto typů, můžeme využít standardní postupy a algoritmy k jeho řešení:
- Plánovací úlohy lze řešit pomocí technik prohledávání stavového prostoru (např. prohledávání do hloubky či do šířky).
- Úlohy splňování podmínek lze řešit například kombinací propagace omezení a prohledávání s návratem (backtracking).
- Optimalizační problémy lze řešit postupným budováním řešení (systematicky či hladově), nebo postupným vylepšováním jednoho či více řešení (lokální prohledávání, genetické algoritmy).
- K predikcím a generování se využívá strojové učení, tedy programy, které se učí z dat nebo zkušenosti. (Této rozsáhlé oblasti věnujeme samostatnou kapitolu.)
Úlohy a metody umělé inteligence
Na první pohled vypadá každý nový problém jinak, ale při vhodné abstrakci se často ukáže, že jde o jeden ze známých typů úloh, pro jehož řešení můžeme využít standardní postupy a algoritmy.
Typy úloh umělé inteligence
Mezi typy úloh řešených v umělé inteligenci patří:
- plánování – nalezení (nejkratší) posloupnosti akcí, která nás dostane do cíle (nalezení cesty z bludiště, poskládání Rubikovy kostky, naplánování cesty auta do zadané lokace, řešení Sokobana, Autíček a podobných logických úloh)
- splňování podmínek – nalezení hodnot proměnných, které splňují různá provázaná omezení (tvorba školního rozvrhu, řešení sudoku a podobných logických úloh)
- optimalizace – hledání hodnot proměnných minimalizující nebo maximalizující zadanou funkci (sbalení batohu s nejvyšší hodnotou vybraných předmětů, hledání receptu na nejlepší sušenky)
- řízení – nalezení strategie předepisující vhodnou akci pro různé situace (hraní šachu, jízda auta mezi dvěma křižovatkami)
- predikce – určení kategorie nebo hodnoty nějakého atributu určitého vzorku (detekce spamu, rozpoznání rostliny na fotce, odhad zítřejších srážek)
- generování – vytvoření textu nebo obrázku na základě jiného textu nebo obrázku (odpovídání na otázky, strojový překlad, vygenerování popsaného obrázku)
Mnohé problémy jsou kombinací více typů úloh. Například problém obchodního cestujícího (úloha najít nejkratší cestu, která projde všemi zadanými městy a vrátí se do výchozího bodu) zahrnuje plánování, optimalizaci i splňování podmínek.
Charakteristiky prostředí
Úlohy můžeme dále rozlišovat podle vlastností prostředí, se kterým program interaguje:
- diskrétní vs. spojité (Je možných stavů a akcí pouze spočetně mnoho, nebo existuje plynulé spektrum?)
- plně vs. částečně pozorovatelné (Máme k dispozici všechny informace o aktuálním stavu?)
- statické vs. dynamické (Vyvíjí se prostředí i během toho, co AI přemýšlí?)
- deterministické vs. stochastické (Je vývoj jednoznačně určen provedenou akcí, nebo hraje roli náhoda?)
- přátelské vs. nepřátelské (Hraje prostředí proti nám?)
Příklady prostředí
Většina čistě logických deskových her pro dva hráče (šachy, go, dáma) jsou diskrétní, plně pozorovatelné, statické, deterministické a nepřátelské. Mnohé karetní hry (Prší, Poker, Bang!) jsou pouze částečně pozorovatelné, kostkové hry jsou stochastické. Řízení autonomního auta je spojité, částečně pozorovatelné, dynamické a stochastické, ale není nepřátelské.
Metody umělé inteligence
Tyto úlohy se řeší kombinací různých přístupů:
- rozklad na jednodušší podproblémy
- systematické zkoušení možností (hrubá síla a techniky prohledávání stavového prostoru)
- postupné vylepšování řešení (např. lokální prohledávání a genetické algoritmy)
- logické a pravděpodobnostní odvozování (pravděpodobnost je důležitá pro práci s nejistotou)
- využití vhledu expertů a heuristik (pravidla, která neplatí vždy, ale často pomůžou)
- učení se z dat nebo zkušenosti (strojové učení)
Prohledávání stavového prostoru
Prohledávání stavového prostoru je základem mnoha technik umělé inteligence, využívá se například pro řešení logických úloh, výběr optimálního tahu, hledání nejkratší cesty nebo plánování akcí robota.
Stavový prostor úlohy se skládá ze stavů (možné konfigurace úlohy) a akcí (přechody mezi stavy). Jeden ze stavů je počáteční a alespoň jeden stav je cílový. Přechody můžou mít přidruženou cenu.
Stavový prostor jako graf
Stavový prostor lze reprezentovat ohodnoceným orientovaným grafem, jehož vrcholy odpovídají stavům a hrany akcím. Graf stavového prostoru je pro většinu praktických úloh příliš velký na to, abychom ho celý zkonstruovali v paměti, ale některé prohledávací algoritmy si postupně budují část tohoto grafu.
Plán je libovolná posloupnost akcí. Řešení úlohy je takový plán, který nás dostane z počátečního stavu do cílového. Optimální řešení je řešení, které má nejnižší cenu. (Cena plánu je nejčastěji součet cen jednotlivých přechodů.)
Příklad stavového prostoru (skřítek na mřížce)
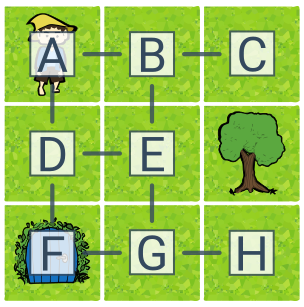
Úlohou je dostat skřítka do domečku. Stavový prostor úlohy má 8 stavů (A–H) a 4 akce (doleva, doprava, dolů, nahoru). Počáteční stav je A, cílový stav F. Optimálním řešením úlohy je např. plán dolů–dolů. Příkladem řešení, které není optimální, je doprava–dolů–dolů–doleva.
Zkoušení všech možností
Nejjednodušším algoritmem, který najde řešení vždy (pokud existuje) je generuj a testuj. Tento algoritmus generuje všechny možné plány a testuje, zda jde o řešení úlohy. Jde tedy o využití hrubé síly, techniky návrhu algoritmů založené na zkoušení všech možností. Zásadní nevýhodou hrubé síly je její časová náročnost. Počet plánů roste exponenciálně vzhledem k délce plánu.
Kolik je různých plánů?
Pokud máme 4 různé akce (P – doprava, D – dolů, L – doleva, H – nahoru), tak existují 4 plány délky 1, ale již 4^2 plánů délky 2 (PP, PD, PL, PH, DP, DD, DL, DH, LP, LD, LL, LH, HP, HD, HL, HH), 4^3 plánů délky 3, 4^4 plánů délky 4, atd.
Obecně, plánů délky n s k akcemi je k^n. Například pro 3 možné akce existuje plánů o 5 krocích 3^5 = 243, plánů o 6 krocích třikrát více, 3^6 = 729, a plánů o 20 krocích je 3^{20}, což už je několik miliard.
Stromové prohledávání
Mnohé plány však nemusí být vůbec proveditelné, nebo se opakovaně vracejí do stejného stavu. Je proto výhodnější testovat plány průběžně po každé akci – jakmile se dostaneme do slepé uličky nebo dříve prozkoumaného stavu, nemusíme žádné další plány začínající touto posloupností akcí prozkoumávat.
Stromové prohledávání je obecný název pro takový způsob prohledávání, kdy postupně konstruujeme a vyhodnocujeme plány po každé akci. Postup prohledávání plánů lze popsat prohledávacím stromem, ve kterém vrcholy reprezentují plány (a současně stav, do kterého se vykonáním plánu dostaneme) a orientované hrany reprezentují akce, které rozšiřují předchozí plán o jeden krok. Prohledávací strom zachycuje stavový prostor tak, jak ho postupně objevuje prohledávací algoritmus. Existuje několik variant stromového prohledávání, které se liší v tom, který plán rozšiřují (tj. který z objevených stavů prozkoumávají jako další):
Prohledávání do hloubky (DFS, angl. Depth First Search) vybírá poslední objevený stav. DFS má dobrou paměťovou složitost, protože si pamatuje pouze plány na aktuální větvi prohledávacího stromu.
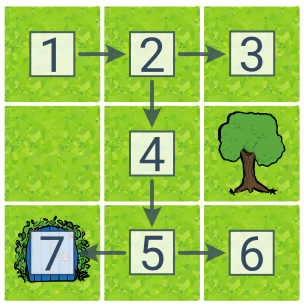
V této ukázce předpokládáme, že DFS zkouší akce po směru hodinových ručiček (doprava–dolů–doleva–nahoru). Čísla u stavů popisují pořadí objevení. Cíl byl nalezen v 7. kroce a nalezený plán má 4 kroky (doprava–dolů–dolů–doleva).
Prohledávání do šířky (BFS, angl. Breadth First Search) prohledává stavy po vrstvách podle počtu akcí od počátečního stavu. To sice zvyšuje paměťovou složitost (je potřeba si pamatovat více stavů), ale vede k nalezení nejkratšího řešení.
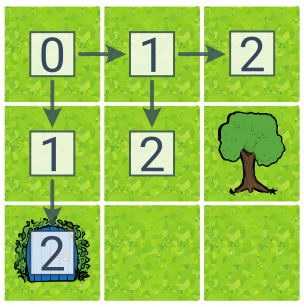
Čísla u stavů v ukázce BFS zachycují vzdálenosti od počátečního stavu, což odpovídá pořadí procházení „po vrstvách“. BFS našlo optimální řešení řešení (dolů–dolů) po prozkoumání 6 stavů.
Prohledávání podle ceny (UCS, angl. Uniform Cost Search) je variací BFS, které umožňuje nalézt nejlevnější řešení, i když mají akce různou cenu. K rozšíření vybíráme plán s nejnižší cenou.
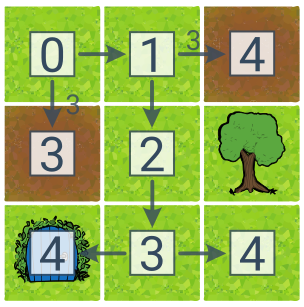
Pro ukázku UCS jsme přidali do plánku dvě hnědé bažiny s třikrát vyšší cenou přechodů. Čísla ve čtverečcích zde zachycují cenu plánu. V tomto případě je nejlevnější řešení (s cenou 4) doprava–dolů–dolů–doleva a UCS ho nalezne. (BFS by vrátilo řešení dolů–dolů s cenou 6.)
Algoritmus stromového prohledávání
Při stromovém prohledávání si udržujeme množinu stavů, které chceme v budoucnu prozkoumat, tzv. okraj. V každém kroku jeden stav z okraje odebereme a do okraje zařadíme jeho následníky (tj. stavy, do kterých se lze dostat z odebíraného stavu jednou akcí). Obecné schéma stromového prohledávání je následovné:
- Zařaď do okraje počáteční stav.
- Opakuj následující kroky, dokud nenajdeš cíl.
- Odeber jeden stav z okraje. Pokud je cílový, skonči.
- Jinak ho expanduj, tj. zařaď do okraje jeho následníky.
- Pokud se vyprázdnil okraj, tak cesta do cíle neexistuje.
Zmíněné varianty stromového prohledávání se liší tím, jakou strategii využívají k výběru stavu z okraje (krok 3), tj. jak implementují okraj. Prohledávání do hloubky (DFS) používá zásobník (odebíráme naposledy vložený stav), prohledávání do šířky (BFS) frontu (odebíráme nejdříve vložený stav) a prohledávání podle ceny (UCS) prioritní frontu (odebíráme stav s nejnižší cenou zatím nejlevnějšího plánu vedoucího do daného stavu).
Abychom se vyhnuli opakovanému prozkoumávání stejných stavů, můžeme si navíc udržovat množinu již prozkoumaných stavů a ty znova neexpandovat. Toto rozšíření se někdy označuje jako obecné grafové prohledávání, aby se odlišilo od stromového prohledávání bez kontroly dříve prozkoumaných stavů. Nevýhodou je zvýšení paměťové náročnosti.
Informované prohledávání
Prohledávání lze urychlit pomocí heuristik poskytujících odhad vzdálenosti do cíle. Taková informace je závislá na konkrétní úloze. Prohledávání využívající heuristiky označujeme jako informované prohledávání. (Algoritmy v předchozích sekcích označujeme naopak jako „neinformované“.)
Hladové prohledávání se řídí pouze hodnotou heuristiky a vybírá vždy akci, která nás dostane nejblíže cíli. Pokud hrozí slepé uličky, je potřeba hladový přístup zkombinovat se stromovým prohledáváním (jde tedy o tzv. hladové stromové prohledávání) – jako další stav vybíráme ten s nejnižším odhadem ceny podle heuristiky. Hladové prohledávání je velmi rychlé, negarantuje však nalezení optimálního řešení.
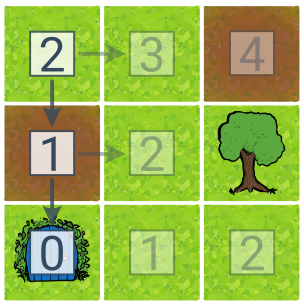
V této ukázce stromového hladového prohledávání odpovídají čísla u stavů heuristickému odhadu ceny do cíle. Heuristikou je vzdálenost od cíle spočítaná jako součet odchylek sloupce a řádku. Algoritmus našel cestu do cíle během dvou kroků, nikoliv však cestu nejlevnější.
A* prohledávání („A star“) kombinuje prohledávání podle ceny (UCS) s heuristikou. Jde o stromové prohledávání, kdy jako další stav vybíráme takový, který má nejnižší součet dosavadní ceny a heuristického odhadu zbývající ceny do cíle. Pokud je heuristika optimistická (poskytuje dolní odhad skutečné ceny), pak A* nelezne optimální řešení a nalezne ho tím rychleji, čím těsnější odhady skutečné ceny heuristika poskytuje.
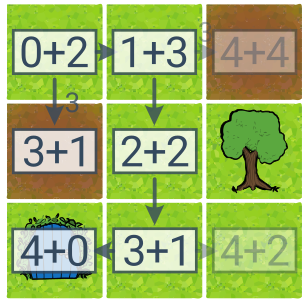
Součet u stavů popisuje prioritu pro A*: [dosavadní cena] + [odhad zbývající ceny]. A* našlo optimální řešení a prozkoumalo přitom méně stavů než UCS (6 místo 8).
Splňování podmínek
Mnoho úloh umělé inteligence lze formulovat jako splňování podmínek. Úloha splňování podmínek je zadaná sadou proměnných, jejich doménami (možné hodnoty) a sadou podmínek na kombinace hodnot proměnných. Ohodnocení (přiřazení hodnot některým proměnným) je řešením úlohy, pokud je úplné (přiřazuje hodnotu všem proměnným) a konzistentní (neporušuje žádnou podmínku). Někdy je navíc zadána účelová funkce určující hodnotu řešení, kterou chceme optimalizovat.
Oblast informatiky zabývající se touto úlohou se označuje jako programování s omezujícími podmínkami. Splňování podmínek je podstatou mnohých logických úloh (např. problém 8 dam, Einsteinova hádanka, algebrogram). Na Umíme si můžete vyzkoušet sudoku, ploty a binární křížovku. Praktickou aplikací je třeba sestavování konfigurací produktu splňující zadaná omezení nebo tvorba rozvrhů (školní rozvrhy, jízdní řády, logistika výroby, rozpis zápasů na turnaji).
Problém 8 dam
Úkol rozestavit na šachovnici 8 dam tak, aby se žádné dvě vzájemně neohrožovaly. (Dáma se může pohybovat o libovolný počet polí vodorovně, svisle i diagonálně.) Úlohu lze zobecnit na „problém N dam“, které máme umístit na šachovnici velikosti N×N.
Einsteinova hádanka
Úkol odvodit vlastnosti několika objektů na základě omezených informací. Nejznámější zadání popisuje pět domů, které stojí vedle sebe, liší se barvou, národností majitelů, jejich oblíbeným nápojem, značkou cigaret a domácím mazlíčkem. K dispozici máme 15 informací typu „Angličan žije v červeném domě.“
Algebrogram
Úkol nahradit písmena za různé číslice tak, aby byl splněný zadaný vzorec. Příklad: SEND + MORE = MONEY.
Řešení úloh splňování podmínek
Jakmile nějaký problém namodelujeme jako úlohu splňování podmínek, lze využít obecné postupy pro jejich řešení. Naivní zkoušení všech možných ohodnocení (generuj a testuj) většinou bude příliš pomalé, protože počet možných ohodnocení roste exponenciálně k počtu proměnných. K řešení se proto typicky používá postupné budování řešení s propagací omezení, nebo postupné zlepšování úplného ohodnocení.
Které problémy jsou těžké?
Obtížnost úloh s omezujícími podmínkami závisí na poměru počtu omezení ku počtu proměnných. Pokud je tento poměr hodně vysoký, nebo naopak hodně nízký, pak bude snadné nějaké řešení nalézt (nebo zjistit, že žádné neexistuje). Představte si sudoku, které má téměř všechna pole vyplněná (je snadné určit zbývající čísla), nebo naopak má vyplněných polí jen pár (existuje mnoho různých řešení).
Postupné budování řešení
Tento přístup spočívá v systematickém zkoušení možných ohodnocení. Na rozdíl od „generuj a testuj“ však ohodnocujeme jednotlivé proměnné postupně a průběžně kontrolujeme, zda nedošlo k porušení některé podmínky. Pokud ano, vyzkoušíme jinou hodnotu. Pokud jsme už vyzkoušeli všechny možné hodnoty dané proměnné, vracíme se k předchozí proměnné a zkusíme změnit její hodnotu (těchto návratů může být libovolné množství). Tomuto algoritmu se říká prohledávání s návratem (backtracking).
Splňování podmínek vs. plánování
Úlohu splňování podmínek lze formulovat jako úlohu plánování, v němž stavy představují různá ohodnocení proměnných, počáteční stav je prázdné ohodnocení, akce odpovídají přiřazení hodnoty do jedné proměnné a cílovým stavem je úplné konzistentní ohodnocení. (Všechna řešení jsou tedy ve stejné hloubce dané počtem proměnných.)
Rozdíl od obecné plánovací úlohy spočívá v tom, že stavy a cíl mají vnitřní strukturu – stav se skládá z hodnot více proměnných, cíl se skládá z více podmínek. Díky této vnitřní struktuře lze úlohy splňování podmínek řešit výrazně efektivněji než obecnými technikami prohledávání stavového prostoru. Můžeme například poznat, že jsme ve slepé větvi, když není některá podmínka splněná. Druhý rozdíl spočívá v tom, že nás nezajímá plán (posloupnost akcí vedoucí do cíle, např. pořadí vyplňování políček sudoku), ale cílový stav (ohodnocení proměnných, např. vyplněné sudoku).
Prohledávání s návratem (backtracking) je v podstatě prohledávání do hloubky (DFS) s včasnou kontrolou porušení podmínek. (Druhým rozdílem je, že nezáleží na pořadí akcí – výsledné řešení je stejné, ať jsme nejdříve přiřadili hodnotu proměnné A nebo B. Při prohledávání s návratem proto stačí prohledávat pouze jedno pořadí proměnných.)
Velký vliv na rychlost prohledávání s návratem mají heuristiky pro výběr proměnné a její hodnoty. Pro výběr proměnné se využívá princip brzkého neúspěchu: vybíráme proměnnou, pro kterou je těžké najít hodnotu (např. tu s nejmenší doménou). Naopak, pro výběr hodnot je vhodnější princip brzkého úspěchu, tedy výběr hodnoty, která by nejspíše mohla být součástí řešení (např. tu, která způsobí nejmenší filtraci domén). Důvod k opačným principům pro výběr proměnné a hodnoty spočívá v tom, že proměnné musíme nakonec projít všechny, ale hodnoty nikoliv.
Prohledávání s návratem lze dále výrazně urychlit propagací omezení. Po každé volbě hodnoty provedeme filtrování domén, čímž se zmenší počet hodnot budoucích proměnných, které bude potřeba zkoušet.
Propagace omezení
Z domén proměnných můžeme bezpečně odstranit hodnoty, pro které nelze splnit některou podmínku (neexistují hodnoty ostatních proměnných v podmínce, pro které by podmínka platila). (Sudoku: Když už je někde umístěná číslice, můžeme ji vyškrtnout z domén všech políček na stejném řádku, sloupci a čtverci.) Pokud zbývá v doméně proměnné jediná možná hodnota, známe část řešení.
Podmínky můžeme kontrolovat opakovaně, dokud se nám daří nějaké hodnoty vyškrtávat. V ojedinělých případech (lehká sudoku) lze opakovaným filtrováním získat celé řešení, častěji však pouze úlohu zjednodušíme a pak je potřeba zkoušet různé možné hodnoty (proto se propagace omezení využívá typicky v kombinaci s prohledáváním s návratem).
Výraznějšího filtrování dosáhneme, když budeme kontrolovat současně splnění více podmínek naráz, nikoliv vždy jen jedné (to ale zvyšuje výpočetní náročnost).
Postupné zlepšování
Alternativou k postupnému budování řešení je začít s kompletním ohodnocením (klidně náhodným) a to postupně vylepšovat drobnými úpravami. Ohodnocení je tedy celou dobu úplné, ale nikoliv konzistentní. Vylepšení je taková změna ohodnocení, která zmenší počet porušených podmínek. Algoritmy postupného zlepšování lze rozdělit do dvou kategorií podle toho, jestli pracují v jeden moment s jediným ohodnocením (lokální prohledávání) nebo s více naráz (prohledávání s populací).
Lokální prohledávání pracuje s jedním ohodnocením, které postupně vylepšuje. Množina všech ohodnocení, které se od toho současného lidí jednou změnou, nazýváme okolí. Metoda největšího stoupání (horolezecký algoritmus) vybírá z okolí to ohodnocení, které vede k nejvýraznějšímu zlepšení. Tímto postupem se rychle dostaneme do lokálního optima, kdy všechny okolní stavy jsou horší. Lokální optimum však nemusí být optimemem globálním, zejména tedy nemusí jít o přípustné řešení.
Proto je potřeba využít meta-heuristiky, které vnáší do prohledávání prvek náhodnosti a tedy šanci uniknout lokálnímu optimu. Příkladem meta-heuristiky je simulované žíhání, při kterém z okolí vybíráme náhodně; pokud je nové ohodnocení zlepšující, tak ho přijmeme, pokud není zlepšující, tak ho přijmeme s určitou pravděpodobností, která se postupně snižuje. Jednoduchou meta-heuristikou je také opakované spouštění lokálního prohledávání z různých náhodných počátečních ohodnocení.
Při prohledávání s populací vylepšujeme mnoho ohodnocení naráz. To umožňuje vybírat nejlepší ohodnocení z aktuální populace a případně různá ohodnocení kombinovat. Příkladem jsou genetické algoritmy inspirované fungováním evoluce. Ohodnocení pokračující do další generace jsou vybírána podle jejich kvality, kombinována („křížení“) a případně drobně náhodně měněna („mutace“). Do této kategorie patří také další algoritmy inspirované přírodou, které využívají velké množství interagujících agentů reprezentujících úplná ohodnocení. (Například při „optimalizaci mravenčí kolonií“ má každý mravenec přidružené ohodnocení a podle jeho kvality vydává různě silnou feromonovou stopu – čím je ohodnocení lepší, tím spíš budou další mravenci zkoušet podobná ohodnocení.)
Optimalizace
Optimalizace znamená hledání nejlepšího řešení. Hledáme hodnoty optimalizovaných proměnných, při kterých je zadaná účelová funkce nejvyšší (maximum), nebo nejnižší (minimum). Optimalizace se využívá například při plánování výroby, rozvrhování dopravy, návrhu telekomunikačních sítí a trénování modelů ve strojovém učení.
Optimalizační úlohy
Maximalizační a minimalizační úlohy lze řešit stejnými technikami, každý maximalizační problém lze totiž převést na minimalizační úlohu (a naopak) převrácením účelové funkce. Různé techniky se však liší v tom, zda je lze použít v diskrétním či spojitém prostoru (ve spojitém prostoru můžou proměnné nabývat libovolných reálných čísel) a zda může problém obsahovat omezující podmínky.
Příklady optimalizačních úloh
Problem batohu. Vybrat kombinaci předmětů, která se vejde do batohu omezené kapacity, aby celková hodnota byla co nejvyšší.
Problém obchodního cestujícího. Najít nejkratší cestu, která projde všemi zadanými městy a vrátí se do výchozího bodu.
Rozvrhování. Najít optimální (nejkratší, nejlevnější) rozvržení aktivit v čase s ohledem na dané zdroje a omezení.
Strojové učení. Zvolit parametry modelu (např. váhy neuronové sítě) minimalizující chybu predikcí na trénovacích datech.
Problém čokoládových sušenek. Najít recept na co nejlepší čokoládové sušenky.
Systematické prohledávání
Nejjednodušším přístupem je zkoušení všech možností (hrubá síla). Ve spojitém prostoru je možností nekonečně mnoho, lze však systematicky vyzkoušet všechny kombinace hodnot s určitým rozlišením (mřížkové prohledávání). Tento přístup je použitelný jen pro velmi malé problémy, protože počet možností roste exponenciálně s počtem proměnných. Při řešení problému batohu můžeme každý předmět buď vzít, nebo nevzít, existuje tedy 2^n možných kombinací předmětů.
Efektivnější je přiřazovat hodnoty proměnným postupně a průběžně odhadovat nejlepší možnou hodnotu řešení s daným částečným přiřazením. Když je tato mez horší než zatím nejlepší nalezené řešení, můžeme celou větev přeskočit a být si jistí, že jsme přitom nepřeskočili optimální řešení. Tato varianta stromového prohledávání se nazývá metoda větví a mezí (angl. branch and bound). Pro výběr dalšího stavu k průzkumu lze využít hladové kritérium – stav s nejlepší hodnotou meze (nebo jinou strategii stromového prohledávání stavového prostoru).
Hladové a náhodné prohledávání
Systematické prohledávání garantuje nalezení globálního optima, velmi často je však příliš pomalé pro praktické problémy. Pro urychlení je potřeba vzdát se požadavku na optimální řešení, pro většinu praktických problémů naštěstí stačí řešení, které je „dostatečně dobré“. K urychlení lze pak využít hladovost a náhodnost.
Hladové prohledávání vybírá pro každou proměnnou hodnotu, která se zdá zatím nejlepší a zpětně se k těmto rozhodnutím nevrací. Při řešení problému batohu bychom mohli brát postupně předměty s nejvyšším poměrem cena/váha, dokud se do batohu vejdou. Hladové prohledávání je sice velmi rychlé, ale nalezené řešení může být hodně špatné. Mezi extrémy hladového prohledávání (zkoušíme jedinou cestu) a systematického stromového prohledávání (zkoušíme všechny cesty) existuje paprskové prohledávání (zkouší fixní počet cest). Paprskové prohledávání ponechává na každé úrovni stromu pouze fixní počet nejlepších stavů a ostatní zahazuje.
Náhodné prohledávání zkoumá náhodně vybraná řešení (místo všech možných). Existují složitější techniky, které postupně zvyšují pravděpodobnost výběru řešení v nadějných oblastech – snaží se vyvažovat průzkum zatím neprobádaných oblastí (náhodnost) a zužitkování informací o více prozkoumaných oblastech (hladovost). Tento kompromis mezi průzkumem a zužitkováním (angl. exploration-exploitation tradeoff) je obecným principem využívaným v mnoha optimalizačních algoritmech.
Hladovost i náhodnost se používají také v rámci metod postupného vylepšování zmíněných v následujících sekcích.
Lokální prohledávání
Alternativou k postupnému budování řešení je začít s libovolným řešením, a to postupně vylepšovat drobnými změnami. Tento přístup se nazývá lokální prohledávání. Množinu blízkých řešení, které se od toho aktuální liší jedinou změnou, nazýváme okolí. (Při řešení problému batohu by okolí mohlo zahrnovat například ty kombinace, které se liší nejvýše jedním přidaným a jedním odebraným předmětem.) Existují různé heuristiky pro výběr dalšího řešení z okolí. Horolezecký algoritmus vybírá některé zlepšující řešení, případně nejlepší řešení z okolí (tato varianta horolezeckého algoritmu se označuje jako metoda největšího stoupání).
S využitím těchto hladových heuristik dorazíme rychle do lokálního optima, tedy řešení, které je nejlepší ve svém okolí, nemusí však jít o globální optimum. Šanci na nalezení globálního optima lze zvýšit využití náhodnosti. Simulované žíhání vybírá z okolí náhodně; pokud je nové řešení zlepšující, tak ho přijmeme, pokud není zlepšující, tak ho přijmeme s určitou pravděpodobností, která se postupně snižuje.
Obdoba lokálního prohledávání ve spojitém prostoru je gradientní sestup. Ve spojitém prostoru lze často vypočítat směr, ve kterém účelová funkce nejrychleji klesá nebo stoupá (tzv. gradient), není pak potřeba testovat různá řešení v okolí. Gradientní sestup se běžně využívá ve strojovém učení, např. pro optimalizaci vah neuronové sítě.
Prohledávání s populací
Při prohledávání s populací vylepšujeme mnoho řešení naráz. To umožňuje vybírat nejlepší řešení z aktuální populace a případně různá řešení kombinovat. Příkladem jsou genetické algoritmy inspirované fungováním evoluce. Řešení pokračující do další generace jsou vybírána podle jejich kvality (hodnoty účelové funkce), kombinována („křížení“) a případně drobně náhodně měněna („mutace“).
Do této kategorie patří také algoritmy inteligence hejna inspirované skupinovým chováním nějakého druhu (typicky při hledání potravy). Tyto algoritmy využívají velké množství jednoduchých agentů reprezentujících různá řešení, kteří spolu nepřímo interagují skrze společnou paměť. Například při optimalizaci mravenčí kolonií má každý mravenec přidružené řešení a na své trase vydává feromonovou stopu, která je tím silnější, čím lepší řešení. Všechny feromonové stopy dohromady tvoří společnou pamětí, podle které se pak řídí další mravenci (preferují cesty s výraznější feromonovou stopou, které se v minulosti osvědčily).
Princip strojového učení
Umělá inteligence často využívá učení z dat, tzv. strojové učení. Vstupem strojového učení je velké množství dat (dataset), výstupem je naučený model pro řešení požadovaného úkolu. Máme-li dostatek dat popisujících vzhled a chování příšerek, můžeme naučit model, který bude pro nové příšerky odhadovat, zda jsou hodné, na základě jejich vzhledu.
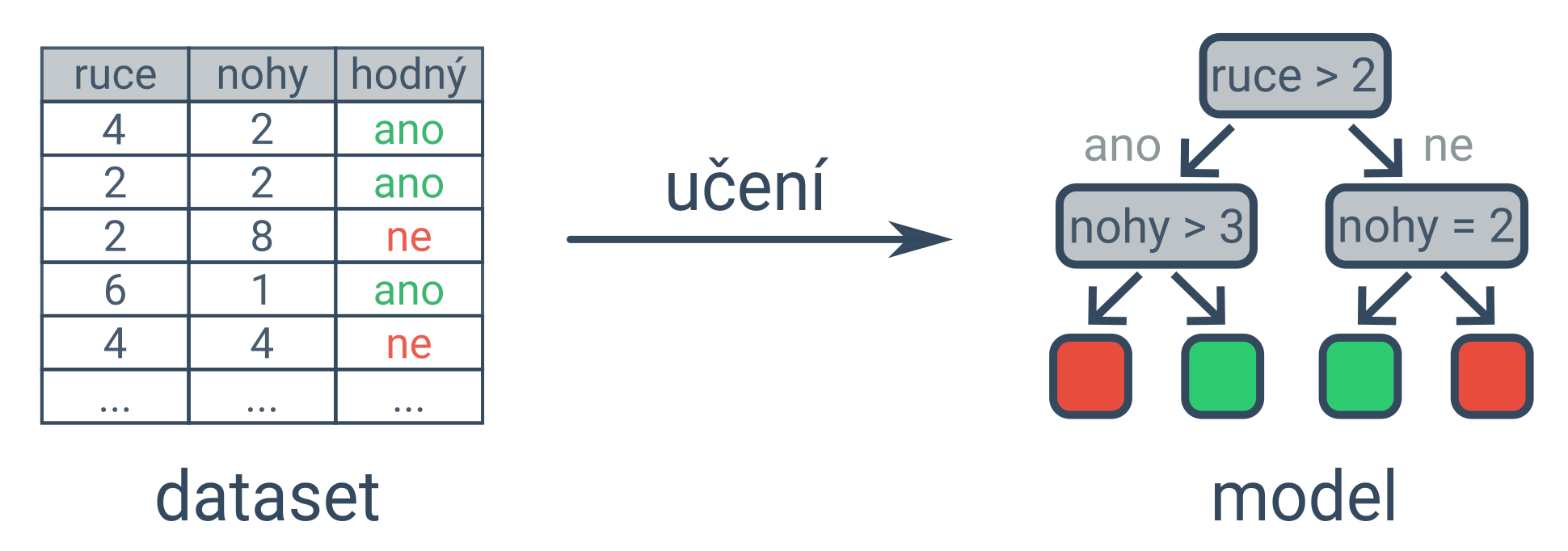
Klíčovou ingrediencí pro strojové učení je velké množství dat. Jednotlivé příklady jsou typicky poměrně jednoduché (např. jedna fotka), ale je jich hodně (někdy i miliony). Aby byl model užitečný, nestačí, aby si zapamatoval trénovací data (memorizace), musí být schopen určovat správný výstup i pro příklady nové (zobecňování, generalizace).
Příkladem modelu je rozhodovací strom (na obrázku výše) nebo neuronová síť (model volně inspirovaný sítí neuronů v mozku). Strojové učení může v závislosti na množství dat trvat vteřiny i celé dny, pro urychlení se proto někdy využívají grafické procesory (GPU, graphics processing unit) a tenzorové procesory (TPU, tensor processing unit).
Strojové učení lze vnímat jako alternativu ke klasickému programování, při kterém programátor zapisuje posloupnost přesných instrukcí (např. if-then pravidla nebo heuristika na základě zkušenosti). Strojové učení bude vhodným přístupem zejména tehdy, když není jasné, jak by takový klasický program měl vypadat a přitom lze sehnat rozsáhlé množství příkladů (např. detekce spamu). Strojové učení spíše nebude vhodným přístupem pro kritická rozhodnutí, kde není tolerovatelná žádná chyba a potřebujeme vysokou předvídatelnost a transparentnost chování (např. bankovní převod).
Aplikace strojového učení (příklady)
- detekce spamu
- diagnóza nemoci
- rozpoznání hlasu
- překlad textů
- doporučování filmů
- řízení auta
- generování obrázků podle popisu
